BestBlogs.dev Highlights Issue #10
Subscribe NowDear friends,
👋 Welcome to this issue's curated article selection from BestBlogs.dev!
🚀 In this edition, we dive into the latest breakthroughs, innovative applications, and industry dynamics in artificial intelligence. From model advancements to development tools, from cross-industry applications to market strategies, we've handpicked the most valuable content to keep you at the forefront of AI developments.
🔥 AI Models: Breakthrough Advancements
1.Google Gemini 1.5 Pro: 2-million token context window with code execution capability 2.Alibaba's FunAudioLLM: Open-source speech model enhancing natural voice interactions 3.Meta's Chameleon: Multimodal AI model outperforming GPT-4 in certain tasks 4.Moshi: Native multimodal AI model by France's Kyutai lab, approaching GPT-4o level 5.ByteDance's Seed-TTS: High-quality speech generation model mimicking human speech
💡 AI Development: Tools, Frameworks, and RAG Technology Innovations
1.LangGraph v0.1 and Cloud: Paving the way for complex AI agent system development 2.GraphRAG: Microsoft's open-source tool for complex data discovery and knowledge graph construction 3.Kimi's context caching technology: Significantly reducing costs and response times for long-text large models 4.Jina Reranker v2: Neural reranker for agent RAG, supporting multilingual and code search 5.Ant Group's Graph RAG framework: Enhancing Q&A quality with knowledge graph technology
🏢 AI Products: Cross-industry Applications
1.Tencent Yuanbao AI Search upgrade: Introducing deep search mode for structured, rich responses 2.ThinkAny: AI search engine leveraging RAG technology, developed by an independent developer 3.Replika: AI emotional companion using memory functions for deep emotional connections 4.AI in sign language translation: Signapse, PopSign improving life for the hearing impaired 5.Agent Cloud and Google Sheets for building RAG chatbots: Detailed implementation guide
📊 AI News: Market Dynamics and Future Outlook
1.Bill Gates interview: AI set to dominate fields like synthetic biology and robotics 2.Tencent's Tang Daosheng on AI strategy: AI beyond large models, focusing on comprehensive layout and industrial applications 3.Gartner research: Four key capabilities for AIGC to realize value in enterprises 4.AI product pricing strategies: Examining nine business models including SaaS and transaction matching 5.Why this wave of AI entrepreneurship is still worth pursuing: Exploring how AI technology changes supply and creates new market opportunities
This issue covers cutting-edge AI technologies, innovative applications, and market insights, providing a comprehensive and in-depth industry perspective for developers, product managers, and AI enthusiasts. We've paid special attention to RAG technology's practical experiences and latest developments, offering valuable technical references. Whether you're a technical expert or a business decision-maker, you'll find key information here to grasp the direction of AI development. Let's explore the limitless possibilities of AI together and co-create an intelligent future!
Table of Contents
- Google Open Sources Gemma2! Best Practices Tutorial for Inference and Fine-tuning on ModelScope Platform
- Alibaba Tongyi Laboratory releases the open-source speech generation model FunAudioLLM, enhancing multi-language audio generation and recognition capabilities through CosyVoice and SenseVoice models.
- Eight People Spent Half a Year to Develop an Open-Source Version of GPT-4o Named Moshi, Supporting Real-Time Interaction and Emotion Recognition with Almost Zero Latency. The Technology Behind It is Revealed, and It's Free for Everyone to Use.
- Context Caching: Revolutionizing Long Text LLMs for Developers | Kimi Open Platform
- Kimi's Inference Architecture Mooncake Supports Over 80% of Traffic
- iFLYTEK StarFire 4.0 Tops Eight Lists, Showcases Voice Recognition Amid Planned Interference
- Meta's Chameleon AI Model Outperforms GPT-4 on Mixed Image-Text Tasks
- Meta's 3DGen System: High-Quality 3D Assets from Text in Under 60 Seconds
- Unveiled: Juewei AI's Trillion-parameter MoE and Multi-modal Large-scale Model Matrix
- Why Does Apple Use Small Models?
- Beginner's Guide to Tuning Hyperparameters for Large Language Models
- ML Engineer Outperforms OpenAI's GPT-4 by Fine-tuning 7 Models
- GraphRAG: New tool for complex data discovery now on GitHub
- Dify v0.6.12: Integrating LangSmith and Langfuse to Enhance LLM Application Observability
- Meituan's Practices in Search Ad Recall Technology
- Kingsoft Office's Thoughts and Practices on Large Models in Knowledge Base Business
- 12 Pain Points of RAG and Their Solutions by a Senior NVIDIA Architect
- Ping An One Wallet: Exploring and Implementing RAG and Other Technologies in ToC Financial Payment Scenarios
- Challenges and Innovations of RAG Implementation in Enterprise Applications (Transcript)
- How to Build a RAG Chatbot with Agent Cloud and Google Sheets
- Announcing LangGraph v0.1 & LangGraph Cloud: Running agents at scale, reliably
- Retrieval-Augmented Generation: Revolutionary Technology or Overpromised?
- Exploration of Multi-Agent System Applications in Financial Scenarios
- Embedded function calling in Workers AI: easier, smarter, faster
- Exploring the Use of Large Language Models to Enhance Courier Services
- Long Document Summarization with Controllable Detail: Exploring Open-Source LLM Tools and Practices
- Seed-TTS: ByteDance's Douyin Voice Synthesis Technology Unveiled
- Developer's Summary: Pitfalls and Insights from Developing AI Search Engine ThinkAny with 170,000 Users in Three Months
- Deep Dive with Greylock Partner: Interview with Replika CEO on AI Emotions and Human Happiness
- The Art of Designing Tool-focused Products
- Figma AI: Empowering Designers Everywhere
- Tencent Yuanbao AI Search Upgrade: Launches Deep Search Mode with Multimodal Interaction Capability
- Chinese LLMs Outperform ChatGPT-4o: An Evaluation of 8 AI Models
- AI is Creating Revolutionary User Interfaces and Products
- The Keynote Speech of Andrej Karpathy at the 2024 UC Berkeley Artificial Intelligence Hackathon [Translation]
- Interview with Tencent's Tang Daosheng: AI Transcends Large Models
- Artificial General Intelligence: What Is It? How to Test It? How to Achieve It? | Research Review
- ByteDance Has No Surplus Funds Left? No More Forever Free GPT-4; Subscription Pricing is Unsuitable for AI Products! Various Pricing Strategies to Make Users Pay | ShowMeAI Daily
- So, are these AI products all dead? Entrepreneurship is a high-stakes game; Independent developers' marketing strategies; Google has shut down more than 300 projects | ShowMeAI
- Why is AI Entrepreneurship Still Worth Pursuing?
Google Open Sources Gemma2! Best Practices Tutorial for Inference and Fine-tuning on ModelScope Platform
Google recently released the Gemma 2 large language model and open-sourced it. The Gemma 2 series offers two scales with 9B and 27B parameters, featuring a new architecture designed for optimal efficiency and performance. The 27B version of Gemma 2 performed excellently in benchmark tests, surpassing models twice its size, setting a new standard for open models. Additionally, the Gemma 2 model can efficiently run inference at full precision on a single Google Cloud TPU host, NVIDIA A100 80GB GPU, or NVIDIA H100 GPU, significantly reducing costs while maintaining high performance, making model deployment more accessible and affordable. The article also details how to configure and install the Gemma 2 model on the ModelScope Platform and provides best practices for inference and fine-tuning, including environment setup, model download, inference code examples, and steps for using the Ollama tool for inference. Furthermore, the article introduces how to use the ms-swift tool to perform Chinese Language Fine-tuning and self-awareness fine-tuning on Gemma 2, and showcases the inference and evaluation effects before and after fine-tuning.
Alibaba Tongyi Laboratory releases the open-source speech generation model FunAudioLLM, enhancing multi-language audio generation and recognition capabilities through CosyVoice and SenseVoice models.
Alibaba Tongyi Laboratory has released the open-source speech generation model FunAudioLLM, aiming to enhance natural speech interaction between humans and large-scale language models (LLMs). FunAudioLLM includes two main models: CosyVoice and SenseVoice. CosyVoice focuses on multi-language audio generation and emotional control, while SenseVoice focuses on high-precision speech recognition and emotion detection. FunAudioLLM can be applied to multilingual translation, emotional speech dialogue, interactive podcasts, and audiobooks. The article provides a detailed introduction to the technical principles and applications of the two models, as well as related open-source repositories and online experience links.
Eight People Spent Half a Year to Develop an Open-Source Version of GPT-4o Named Moshi, Supporting Real-Time Interaction and Emotion Recognition with Almost Zero Latency. The Technology Behind It is Revealed, and It's Free for Everyone to Use.
This article introduces Moshi, a native multi-modal AI model developed by Kyutai Lab from France. The model reaches and is close to the level of GPT-4o, with real-time listening, speaking, and emotion recognition capabilities. The development team of Moshi only consists of eight people, and it took them half a year to complete the training with 1000 GPUs. Moshi is designed to understand and express emotions, supporting 70 different emotions and speaking styles. It can simultaneously process both audio streams for listening and speaking, achieving a minimum end-to-end latency of 160ms. The model training is based on Helium-7B and the internal Mimi model, with audio recordings by professional voice actors for fine-tuning. Moshi will be open-sourced and is available for experience through a waiting list. Kyutai Lab is committed to open source and open science, with team members from strong backgrounds and funds from private sponsors and donations, using high-performance computing devices for development.
Context Caching: Revolutionizing Long Text LLMs for Developers | Kimi Open Platform
This article introduces the new Context Caching technology by the Kimi Open Platform. This technology pre-stores frequently requested data, allowing quick retrieval from the cache rather than recalculating or fetching from the original source. This significantly reduces the cost and response time for long-text LLMs. In practical applications, Context Caching can reduce costs by up to 90% and the response time of the first token by 83%. The article provides detailed API steps for creating and using caches, demonstrates the actual effects and billing model, and invites developers to participate in the public beta. Specific application scenarios and code examples are also included to help readers better understand and apply the technology.
Kimi's Inference Architecture Mooncake Supports Over 80% of Traffic
This article introduces Mooncake, the inference architecture behind Kimi. The architecture addresses the challenge of large traffic through separation design and KV cache optimization. Mooncake consists of a global scheduler, Prefill node cluster, Decoding node cluster, and a distributed KVCache pool, utilizing RDMA communication components for efficient data transmission. Mooncake implements a predictive rejection strategy to handle load fluctuations and large traffic, significantly improving system performance. Experimental results show that Mooncake can increase throughput by up to 525% and handle 75% more requests in real scenarios. Future optimizations will aim to meet more complex load and scheduling requirements.
iFLYTEK StarFire 4.0 Tops Eight Lists, Showcases Voice Recognition Amid Planned Interference
iFLYTEK's StarFire 4.0 demonstrates impressive voice recognition capabilities, even under strong interference, including three people speaking simultaneously and background music. The new version has enhanced seven major capabilities and topped eight lists, fully competing with GPT-4 Turbo. It also features an upgraded StarFire APP/Desk and voice model, with a new content溯源 function. The voice recognition accuracy reaches 91% in dual-speaker scenarios and 86% in triple-speaker scenarios, showing significant improvement in noise resistance.
Meta's Chameleon AI Model Outperforms GPT-4 on Mixed Image-Text Tasks
/filters:no_upscale()/news/2024/06/meta-chameleon-ai/en/resources/1chameleon-architecture-1718803086759.png)
The Fundamental AI Research (FAIR) team at Meta recently released Chameleon, a mixed-modal AI model that can understand and generate mixed text and image content. In experiments rated by human judges, Chameleon's generated output was preferred over GPT-4 in 51.6% of trials, and over Gemini Pro in 60.4%. Key points include:
- Chameleon uses a single token-based representation for both text and image.
- The model was trained on over four trillion tokens of mixed data.
- Chameleon achieved state-of-the-art performance on visual question answering and image captioning tasks.
- The model introduces novel techniques for stable and scalable training.
- Meta faced challenges in scaling the model and had to modify the Transformer architecture.
Meta's 3DGen System: High-Quality 3D Assets from Text in Under 60 Seconds

This article introduces Meta's latest 3DGen system, which can generate high-quality 3D assets from text in under a minute. The article first outlines the challenges in the 3D generation field, such as high artistic quality requirements, insufficient data, slow generation speed, and high computational demands. Meta 3DGen uses a two-stage method, including AssetGen for creating 3D meshes and TextureGen for generating textures, and supports Physically Based Rendering (PBR). Experimental results show that 3DGen outperforms existing mainstream solutions in both speed and quality, especially in handling complex prompts. The article also compares 3DGen's performance with other 3D generation models and explores the commercial potential of 3D generation technology.
Unveiled: Juewei AI's Trillion-parameter MoE and Multi-modal Large-scale Model Matrix
At the 2024 WAIC, Juewei AI showcased its latest AI technology, including the Trillion-parameter MoE Model Step-2, the Hundred-billion-parameter Multi-modal Model Step-1.5V, and the Image Generation Model Step-1X. These models embody Juewei AI's innovation and strength in large-scale model technology. The Step-2 model has comprehensively improved its abilities in mathematical logic, programming, Chinese and English knowledge, and instruction following. It broke through the performance limit by using completely self-developed training methods. The Step-1.5V Multi-modal Model significantly improves its perception and advanced reasoning abilities through the supervision of the Step-2 model. Step-1X performs excellently in image generation and semantic alignment, and has been optimized for Chinese elements. Through these technologies, Juewei AI demonstrated its AI interactive applications, such as the "AI + Havoc in Heaven" project. Founder Jiang Daxin proposed the Three Stages of Large-scale Model Evolution theory, emphasizing the importance of Trillion-parameter and multi-modality fusion, demonstrating Juewei AI's leading position and future potential in the domestic AI field.
Why Does Apple Use Small Models?
At WWDC 2024, Apple unveiled Apple Intelligence, deeply integrated into iOS 18, iPadOS 18, and macOS Sequoia. Apple opted for a pragmatic approach by using small models to optimize user experience rather than pursuing larger models. Apple Intelligence can adapt instantly to users' daily tasks and can run on the device side or be supported through private cloud servers. The basic model is trained using the AXLearn framework, which employs multiple parallel techniques and efficient data management strategies to ensure model performance and data privacy. Apple also developed the Rejection Sampling Fine-tuning algorithm and Reinforcement Learning from Human Feedback (RLHF) algorithm to significantly improve the quality and efficiency of model instruction compliance. To further optimize on-device performance, Apple employs low-bit quantization and intelligent cache management, enabling the iPhone 15 Pro to achieve low latency and high token generation rates. Adapter technology is also used to fine-tune the basic model for specific tasks while preserving the model's general knowledge. Through multidimensional testing and manual evaluation, Apple has demonstrated that its model is superior to competitors in summary generation, basic functionality, security, and instruction compliance.
Beginner's Guide to Tuning Hyperparameters for Large Language Models
This article offers a comprehensive introduction to hyperparameters in large language models (LLMs) and their crucial role in the model training and optimization process. Hyperparameters are determined before training begins and directly impact the learning process and the model's performance. The article examines the settings and effects of key hyperparameters, including model size, number of epochs, learning rate, batch size, maximum output tokens, decoding type, Top-k and Top-p sampling, temperature, stop sequences, frequency, and presence penalty. It also introduces automated tuning methods such as random search, grid search, and Bayesian optimization, highlighting their importance in enhancing the efficiency and effectiveness of hyperparameter tuning. Ultimately, the article concludes that hyperparameter tuning is not merely a technical task but an art that demands continuous exploration and adaptation.
ML Engineer Outperforms OpenAI's GPT-4 by Fine-tuning 7 Models
This article details how a machine learning engineer fine-tuned seven open-source large language models, achieving superior performance to OpenAI's GPT-4 on test datasets. Fine-tuning involves further training pre-trained large language models on specific datasets to enhance their performance on targeted tasks. The author emphasizes the significance of fine-tuning in the era of large models, particularly when precise control and optimization are crucial. The article addresses challenges encountered during fine-tuning, such as code complexity, execution speed, and parameter selection, and illustrates how to load datasets, conduct evaluations, and store prediction results. Through experimental comparisons, the author demonstrates that fine-tuned models excel in event prediction, data extraction, and other tasks, significantly outperforming GPT-4 in certain areas.
GraphRAG: New tool for complex data discovery now on GitHub
Microsoft Research has launched GraphRAG, a tool that leverages a large language model to extract a rich knowledge graph from text documents, now available on GitHub. This graph-based approach reports on the semantic structure of data, detecting communities of densely connected nodes to create hierarchical summaries. GraphRAG addresses limitations in naive RAG approaches by providing community summaries that consider the entire dataset, enabling better answers to global questions. Evaluations show that GraphRAG outperforms naive RAG in comprehensiveness, diversity, and empowerment. Microsoft has also released a solution accelerator for GraphRAG, aiming to make graph-based RAG more accessible for global-level data understanding.
Dify v0.6.12: Integrating LangSmith and Langfuse to Enhance LLM Application Observability
Dify version 0.6.12 integrates LangSmith and Langfuse, simplifying monitoring and optimization of LLM applications. LangSmith provides deep tracing and evaluation for complex applications. Langfuse, known for its low performance overhead and open source features, is suitable for self-deployed users. Through simple configuration, users can obtain detailed performance and cost data, optimizing application quality and efficiency. This Dify update sets new benchmarks for transparency and efficiency in developing LLM applications.
Meituan's Practices in Search Ad Recall Technology

The article "Meituan's Practices in Search Ad Recall Technology", authored by Meituan's technical team, details Meituan's exploration and application of search ad recall technology. It begins by analyzing traffic characteristics and challenges associated with Meituan's search ads, highlighting issues such as the poor content quality of merchants and the predominance of product intent in search queries. To address these challenges, Meituan initiated the development of search ad recall technology in 2019, progressing through three key stages: multi-strategy keyword mining, layered recall systems, and generative retrieval. In the multi-strategy keyword mining stage, Meituan employed rule-based strategies and gradually integrated model-based methods, including both extractive methods that identify keywords from existing data and generative methods that create new keywords. As technology advanced, Meituan shifted its focus to generative mining, leveraging large language models to surpass literal limits and explore broader traffic opportunities. During the layered recall systems stage, Meituan utilized both offline and online recall methods, enhancing online matching efficiency through keyword mining and query rewriting. In the generative retrieval stage, Meituan concentrated on generative keyword recall and multimodal generative vector recall, improving vector representation and keyword generation consistency. Additionally, the article discusses Meituan's efforts in building advertising large language models, optimizing the recall efficiency of offline keywords by integrating domain and scene knowledge. The article concludes by summarizing Meituan's practical experiences and future directions in generative retrieval, emphasizing the advantages of generative algorithms in expanding recall strategy space.
Kingsoft Office's Thoughts and Practices on Large Models in Knowledge Base Business
In Kingsoft Office's latest article, we explore the application practices of large-scale language models (LLMs) in knowledge base services. The article outlines how Kingsoft Office is propelling the intelligent evolution of knowledge base services through three primary avenues: AI Hub, AI Docs, and Copilot Pro. AI Hub functions as an intelligent foundation, facilitating the efficient utilization of large models alongside enterprise-grade security management. AI Docs harnesses Kingsoft Office's document processing expertise, combined with large models, to elevate the intelligent engagement with documents. Designed to enhance work efficiency and cut down on enterprise expenses, Copilot Pro serves as an agent product.
The article lays special emphasis on the development of intelligent question-answering systems, underscoring the significance of parsing heterogeneous documents, executing precise retrievals, and maintaining data security controls. Intelligent content creation is achieved through theme matching, outline drafting, and Prompt refinement, ensuring content accuracy and variety. Furthermore, the creation of an intelligent resume repository, enabled by structured data extraction, significantly boosts recruitment efficiency for enterprises.
We posit that the deployment of large models in enterprise settings necessitates both technological innovation and a thorough grasp of data security and operational efficiency. The article introduces four critical aspects for the successful application of large models: design, data, optimization, and navigating challenges, to guarantee the precision and efficacy of their use. Looking ahead, we foresee large model technology becoming increasingly embedded in specific industry applications, enabling open empowerment. Additionally, we expect a convergence of theoretical research with practical implementation to foster the ongoing progression of large model technologies.
12 Pain Points of RAG and Their Solutions by a Senior NVIDIA Architect

This article focuses on the 12 pain points that Retrieval-Augmented Generation (RAG) technology may encounter in practical applications and provides solutions to these issues. Pain points include missing content, missing top-ranking documents, incorrect detailed instructions, scalability issues in data ingestion, structured data question answering, extracting data from complex PDFs, backup models, and LLM security. NVIDIA Senior Architect Wenqi Glantz offers a series of solutions, including data cleaning, better prompt design, hyperparameter tuning, re-ranking, query transformation, etc. The article also introduces tools and frameworks such as LlamaIndex, LangChain, and NeMo Guardrails. These tools can help improve the retrieval performance and security of RAG models. With these methods and tools, RAG technology can more effectively handle complex queries, improve response accuracy, and ensure the security of generated content.
Ping An One Wallet: Exploring and Implementing RAG and Other Technologies in ToC Financial Payment Scenarios
This article provides a comprehensive overview of Ping An One Wallet's digital transformation initiatives in financial payment, focusing on the application of RAG and vector search technologies in ToC scenarios. The article highlights the challenge faced by payment companies: balancing user convenience and security with personalized experiences, all within a framework of strict policy and ethical considerations. Ping An One Wallet showcases its strategic approach to deploying large language models by drawing upon practical experience in scenario selection, technology implementation, and regulatory compliance. The article further delves into the key steps and iterative processes of their annotation platform, along with practical applications of Function Calling & Agent within their risk control system. Finally, it offers unique insights into the responsibilities of a large language model application architect.
Challenges and Innovations of RAG Implementation in Enterprise Applications (Transcript)
This article is a sharing by Lu Xiangdong at the Xitu掘金 Developer Conference RAG Special Session, focusing on the challenges and innovative solutions encountered by RAG (Retrieval-Augmented Generation) in enterprise application deployment. The article initially addresses the challenges in document parsing, such as handling old file formats (e.g., .doc), complex PDFs, and layout recognition, suggesting solutions leveraging technologies like OCR and PDFBox. It then discusses the integration of structured data with RAG, emphasizing the maintenance of data structure clarity through metadata and data-func methods. The third challenge involves enhancing retrieval capabilities through metadata management and hybrid retrieval, thereby improving retrieval effectiveness. Finally, the article introduces the innovative applications of the rerank model in result ranking and original text display, among other aspects. Following that, the author shares three enterprise deployment application cases: automatic generation of financial research reports, retail shopping assistants, and contract pre-review systems, briefly introducing the specific effects and feedback of each application case. Lastly, Lu Xiangdong presents three insights on the deployment of large models in enterprises: small functionality, high quality, and great value, emphasizing the importance of enterprise deployment services and the concept of dynamic technical advantages.
How to Build a RAG Chatbot with Agent Cloud and Google Sheets

The article begins by highlighting the challenges companies face with data silos and the potential value of data in improving decision-making. It introduces Retrieval-Augmented Generation (RAG) technology as a solution, combining retrieval-based techniques with generative AI tools. The focus then shifts to Agent Cloud, an open-source platform that simplifies the process of building RAG chat applications. The author details their journey with Agent Cloud and the platform's capabilities. The guide walks through setting up Agent Cloud, integrating it with Google Sheets, and creating a RAG chat app. It also discusses the challenges of building a RAG chatbot without Agent Cloud, such as data retrieval and management, NLP, scalability, and user experience. The article concludes with a comprehensive step-by-step guide on setting up Agent Cloud, integrating models, creating a GCP service account key, enabling the Google Sheets API, and setting up data sources.
Announcing LangGraph v0.1 & LangGraph Cloud: Running agents at scale, reliably
The article outlines the launch of LangGraph v0.1 and LangGraph Cloud, two key tools designed to enhance agentic workflows for AI systems. LangGraph offers developers granular control over agentic tasks, including decision-making logic, human-agent collaboration, and error recovery. It supports both single-agent and multi-agent architectures, ideal for complex applications. LangGraph Cloud, designed for scalable deployment, manages fault tolerance, task distribution, and real-time debugging. Key testimonials from major companies like Replit, Norwegian Cruise Line, and Elastic showcase the platform's value in real-world AI use cases, while the article encourages developers to experiment with LangGraph via GitHub and LangGraph Cloud’s waitlist.
Retrieval-Augmented Generation: Revolutionary Technology or Overpromised?
Retrieval-Augmented Generation (RAG) technology significantly enhances the capabilities of generative models by integrating the most up-to-date external information. This enables AI systems to deliver more accurate and contextually relevant responses. The article delineates the key steps in the RAG workflow: initiating a query, encoding the query for retrieval, locating pertinent data, and generating a response. It further elaborates on the multi-faceted process of developing a RAG system, which involves collecting customized data, segmenting and formatting the data, transforming the data into embeddings, devising advanced search algorithms, and crafting a prompt system to guide the generative model.
Despite the increased accuracy that RAG brings, the article acknowledges that it is not a one-size-fits-all solution and necessitates tailored approaches for different projects. RAG encounters several challenges in real-world applications, such as ensuring the reliability of information, managing nuanced semantic variations within dialogues, navigating extensive databases, and mitigating the "hallucination" phenomenon where AI invents information in the absence of data.
The article underscores critical insights gained from implementing RAG, highlighting the importance of adaptability, the need for ongoing refinement, and the significance of effective data management. It also outlines potential future directions for RAG, suggesting that advancements in natural language processing and machine learning could lead to more sophisticated models capable of understanding and processing user queries with greater precision.
Exploration of Multi-Agent System Applications in Financial Scenarios
This article details the speech by Chen Hong, a senior algorithm expert at Ant Group, at the AICon Global AI Development and Application Conference, discussing the application of multi-agent system technology in the financial field. The article focuses on the role of multi-agent systems in addressing challenges of information, knowledge, and decision-intensive environments in finance. By examining the technical evolution of large models and agents, the article highlights the stateful nature of agents and their critical role in task execution. Subsequently, the article proposes solutions for multi-agent system applications in financial scenarios, especially the application of the PEER Model in enhancing the rigor and professionalism of financial decision-making. Finally, the article showcases practical application cases of Ant Group based on the AgentUniverse (a multi-agent framework) framework, illustrating how the PEER Model improves analyst productivity across multiple financial scenarios.
Embedded function calling in Workers AI: easier, smarter, faster
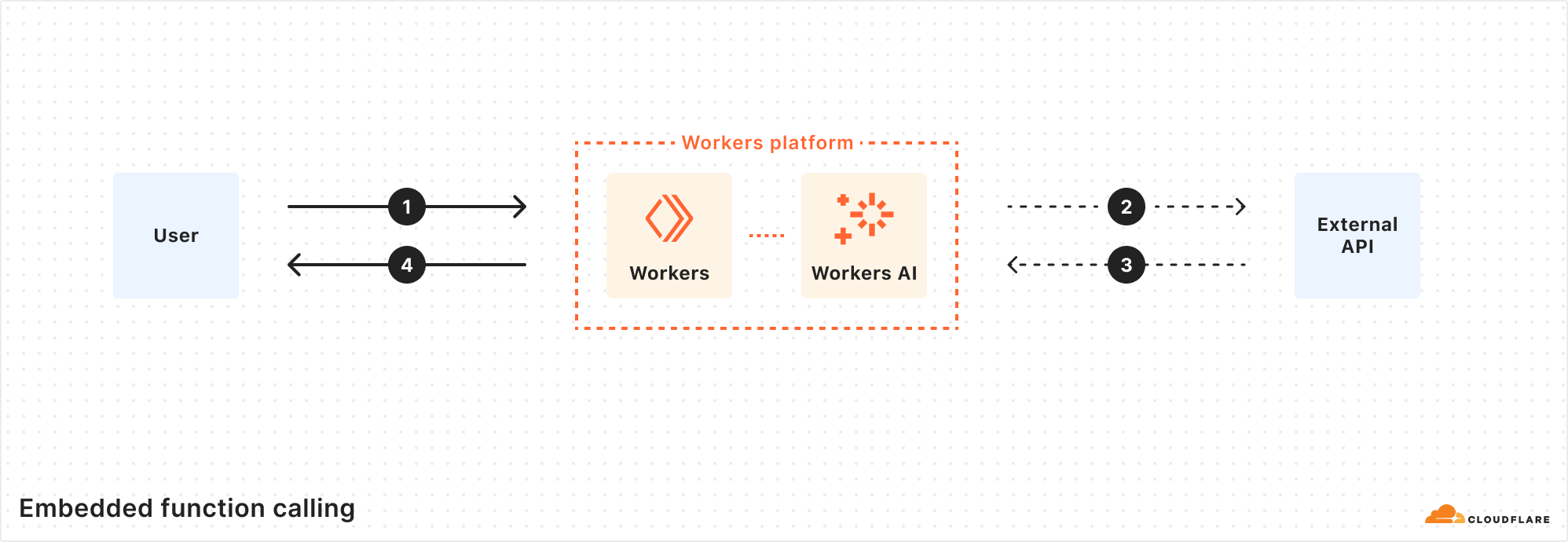
Cloudflare has announced a novel approach to function calling that co-locates LLM inference with function execution, significantly simplifying the development process for AI applications. This new method, called embedded function calling, eliminates the need for multiple network round-trips by running both the LLM inference and function execution in the same environment. To further enhance the developer experience, Cloudflare has released a new npm package, @cloudflare/ai-utils, which includes tools like runWithTools and createToolsFromOpenAPISpec. These tools streamline the process of function calling by dynamically generating tools from OpenAPI specs and executing function code in a single step. Cloudflare's approach aims to match the developer experience offered by OpenAI but with the added benefit of supporting open-source models. The company's Workers AI platform provides a comprehensive environment for inference, compute, and storage, making it easier for developers to build complex AI agents with fewer lines of code.
Exploring the Use of Large Language Models to Enhance Courier Services
This article explains how JD Logistics uses large language models like GPT to boost courier efficiency. It covers the basic principles, such as content generation and reinforcement learning with human feedback (RLHF), and gives examples of their application in courier tasks such as collection, delivery, station operations, and customer service. The article shows how combining speech and large language models can automate tasks like speech recognition, intent recognition, and information extraction, reducing the couriers' workload. It also describes an intelligent Q&A system that uses Prompt+retrieval-augmented generation (RAG) to improve answer accuracy. Additionally, the intelligent prompt function is discussed, which simplifies complex documents into actionable prompts, enhancing courier work quality. Finally, future prospects and areas for further exploration, such as model orchestration, domain-specific training, and safety, are considered.
Long Document Summarization with Controllable Detail: Exploring Open-Source LLM Tools and Practices
This article originates from a practice in the OpenAI cookbook and aims to demonstrate how to efficiently summarize long documents using Large Language Models (LLM). Traditional methods of directly inputting long documents often result in overly short summaries. Therefore, this article proposes a method of segmenting documents and processing them to generate complete and detailed summaries through multiple LLM queries. The main tools used are the Qwen2 model, along with Ollama and transformers for model loading, deployment, and API calls. The specific steps include running the Qwen2 model, installing dependencies, reading and checking document length, calling the OpenAI-formatted API to generate summaries, defining document splitting functions, and finally implementing a controllable detail summary function. This method enables recursive summarization, improving coherence, and allows the adjustment of parameters to generate summaries with different levels of detail, including the addition of custom instructions.
Seed-TTS: ByteDance's Douyin Voice Synthesis Technology Unveiled
Seed-TTS is the latest voice generation model developed by ByteDance's Douyin large model team. It can generate voices that are almost indistinguishable from real human voices, including imperfections in pronunciation. The model is particularly good at learning and imitating human speech. For example, given a voice sample, Seed-TTS can generate new speech with the same characteristics as the original. It can also generate English voices that mimic the characteristics of the Chinese speaker. Seed-TTS can also customize voice tones, such as adding a 'coquettish' tone. It can even generate speech for different characters and emotions based on a novel's plot and character traits. The technology has been used in C-end products and received positive feedback. The team shares insights into the technology's highlights, research value, and challenges overcome.
Developer's Summary: Pitfalls and Insights from Developing AI Search Engine ThinkAny with 170,000 Users in Three Months
This article is a summary of the experience of individual developer Ai Dou Bi developing and launching the AI search engine ThinkAny. ThinkAny is an AI search engine that uses Retrieval-Augmented Generation (RAG) technology to search faster and provide more accurate answers. The article introduces ThinkAny's positioning, operational status, and cold-start process. It also shares the author's views on the AI search market. The author used OpenAI's GPT-3.5-turbo as the base model, set prompts, and requested the large model to output Q&A, focusing on accuracy, response speed, and stability. The article details solutions for selecting the base model, managing context information density, and caching historical conversations. It also shares product features and cold start experiences. Future development directions include platformization, intent recognition, multi-source aggregation, as well as custom information sources. The article also explores the two modes of AI search engines: large model Q&A mode and workflow mode, and their respective advantages and disadvantages. Finally, the author emphasizes the importance of accuracy, model selection, differentiated innovation, and continuous optimization in AI search, and shares some experiences and future plans in the development process.
Deep Dive with Greylock Partner: Interview with Replika CEO on AI Emotions and Human Happiness
This article covers Replika founder Eugenia Kuyda's in-depth discussion on AI emotions, memory functions, and optimizing human happiness through AI companions in an interview hosted by Greylock partner Seth Rosenberg. Replika aims to establish relationships with users that can enhance emotional health, improve emotional states, and foster close social connections. Eugenia emphasized that memory function is at the heart of Replika, enabling users to form deep emotional bonds through shared experiences and memories. She pointed out that AI companions are not just for saving time but also for spending high-quality time with users. Future AI companions will come in various forms and functions to meet different users' needs. Replika 2.0 will focus on providing enjoyable activities and shared experiences. The article also notes that successful AI companion products must combine technical capability with emotional warmth to truly improve user emotional experiences and quality of life.
The Art of Designing Tool-focused Products
This article begins by defining tool-focused products and their core value, then elaborates on their design principles and methods. It emphasizes that the core of tool-focused products is 'Save time', highlighting the sustained impact of solving specific problems. Through a detailed analysis of productivity tool interaction design, the author proposes key design elements such as stable frameworks, operational efficiency, contextual menus, and direct manipulation. The article also explores future trends like AI-assisted features, Product-Led Growth (PLG), and cloud-based collaboration, pointing the way for tool-focused product design. Notably, it provides in-depth discussions on the profound impact of PLG models and AI technology on market promotion and industry transformation.
Figma AI: Empowering Designers Everywhere
At Config2024, Figma announced a range of new features, including Figma AI, aimed at solving real-world problems faced during the design process to enhance efficiency and creativity. Figma AI streamlines the workflow for designers with features such as visual and AI-enhanced content search, auto-naming layers, text processing, and visual layout generation. Additionally, Figma has made five major optimizations to the UI interface, making it easier for users to get started. Figma also released a new version of Figma Slides, further enhancing its competitiveness in the professional environment. Figma has committed to data privacy protection to ensure the security of user data.
Tencent Yuanbao AI Search Upgrade: Launches Deep Search Mode with Multimodal Interaction Capability
Tencent Yuanbao AI Search has been upgraded and launched the Deep Search Mode. The updated version will expand the scope of users' questions in the AI deep search mode, providing more structured and richer answers from both depth and breadth, and simultaneously generating content outlines, mind maps, and summaries of related people and events to help users understand the search content from multiple perspectives. Data show that of all large language model (LLM) related products, more than 65% of users' needs are concentrated on improving work and learning efficiency, with 'search Q&A' requirements accounting for up to 45%. Tencent Yuanbao has optimized the accuracy and relevance of search results based on search engines such as WeChat Search and Sogou Search, and provided detailed source indexing, reducing the credibility issues caused by model hallucinations. This upgrade of Deep Search Mode is particularly prominent in professional fields such as scientific research and finance, providing multidimensional in-depth analysis of issues, leveraging Tencent's ecosystem and other high-quality content sources to provide comprehensive and detailed answers. Users can also further inquire through multi-turn dialogue in Deep Search Mode to obtain more detailed and personalized search and Q&A. Tencent Yuanbao is an AI-native application launched by Tencent based on LLM, with multimodal interaction capability and one-stop services such as AI search, summarization, and writing. It can handle various file formats and generate various data charts. The launch of Deep Search Mode will further meet the information acquisition needs of users in professional and complex topics and comprehensively enhance the search experience.
Chinese LLMs Outperform ChatGPT-4o: An Evaluation of 8 AI Models
This article provides a comprehensive evaluation of 8 large language models in AI machine translation, covering various scenarios such as classical literature, professional literature translation, and daily life communication. The article analyzes each model with specific evaluation criteria, scoring standards, and evaluation questions. The key models evaluated include ChatGPT-4o, Tencent Yuanbao, and iFlytek Spark, which demonstrate different strengths in translating classical Chinese literature, poetry, scientific papers, and more. Chinese large language models, in particular, outperform ChatGPT-4o in several translation tasks, such as translation quality, efficiency, and professional literature translation. The article also covers multimodal recognition and translation of minority languages and evaluates the performance of each model in these complex tasks. Finally, the article summarizes the practical value of high-quality machine translation and predicts future trends in AI translation technology.
AI is Creating Revolutionary User Interfaces and Products
This article delves into the current trends and future directions of AI native applications, providing detailed insights from various perspectives such as brand strategy, real-time and non-real-time interactions, and contextual reasoning. The author cites multiple industry experts to emphasize the significance of innovative user interfaces and product designs in the AI domain. Breakthroughs in AI depend not only on data and computing power but also on discovering the right user interfaces and product forms. AI can tackle the 'blank page problem'—where starting from scratch is often the hardest part—through multimodal interactions and iterative optimization, offering startups opportunities to innovate from the ground up. The author also invites AI native application teams interested in expanding into overseas markets to get in touch for potential investment and incubation opportunities.
The Keynote Speech of Andrej Karpathy at the 2024 UC Berkeley Artificial Intelligence Hackathon [Translation]
In his keynote speech at the 2024 UC Berkeley Artificial Intelligence Hackathon, Andrej Karpathy reviewed his 15-year career in the field of artificial intelligence and shared his insights on its future development. He pointed out that AI has evolved from a small circle of scholars discussing mathematical details to a vibrant stage of large-scale applications, driven by a paradigm shift in computing. He compared large language models to new operating systems and expressed high expectations for their future applications. Karpathy emphasized the importance of starting with small projects and illustrated, through his own experience, how to gradually achieve bigger goals by accumulating experience and skills. He mentioned his work experience at OpenAI, Tesla, and other companies, illustrating how he gradually developed small projects into significant, industry-changing initiatives. He also emphasized the importance of continuous learning and practice, citing the 10,000 Hour Rule to encourage developers to accumulate experience through a lot of practice, leading to success in the field of AI. Moreover, he discussed specific predictions and recommendations for the future development of AI, believing that AI will be widely applied in more practical scenarios.
Interview with Tencent's Tang Daosheng: AI Transcends Large Models
This article delves into Tencent's AI strategy and layout through an interview with Tang Daosheng, CEO of Tencent Cloud and Smart Industries. Tang asserts that AI should not be limited to large models; Tencent must maintain resource investment and follow-up, while also adopting a comprehensive perspective, not equating AI with large models. Tencent's AI framework encompasses infrastructure, model management tools and engine frameworks, large models and model marketplaces, and application scenarios. He particularly emphasizes the need for AI to be applied in industrial scenarios, highlighting the necessity of providing tools for data analysis and capabilities for system integration. Tang also notes that, although large model price reductions will not significantly impact Tencent, the company prioritizes sustainable development, focusing on business models and cost control. In the realm of large model applications, startups can gain market share through differentiated competition and entering markets unfamiliar to large companies. Tencent's approach is to focus on the long-term planning of technology, products, and markets. Tang believes that Tencent's success lies not just in following trends but in continuously refining products, enhancing experiences, and earning user trust. He also shares insights on Tencent's organizational changes and individual development, stressing the importance of each individual's role in the innovation process. Tang further discusses Tencent Cloud's management experience and perspectives on the cloud computing market, underscoring the significance of adjusting rules and the pivotal role of proactive thinking. Additionally, he advocates for Tencent to remain open and curious, actively investing in long-term technological transformations.
Artificial General Intelligence: What Is It? How to Test It? How to Achieve It? | Research Review
This article delves into the working definition, measurement methods, and research paths of AGI. It also analyzes recent hot topics from the perspective of AGI, such as world models, large model illusions, AI explainability, alignment, and brain-like intelligence. The article first introduces the concept and history of AGI, then discusses its definition, measurement methods, and research paths. AGI is defined as a system with autonomy, adaptability, and creativity, with measurement methods including task completion, adaptability, creativity, and intelligence level. The article explores multiple challenges to achieving AGI, such as knowledge representation, natural language processing, perception, and autonomy. Existing testing benchmarks have limitations, and measuring intelligence requires comprehensive consideration of adaptation speed, adaptation quality, and generalization quality. Creating a unified theory of intelligence is crucial for guiding AGI research and verifying correctness. Finally, the article calls on researchers to independently think and carefully choose research paths based on a full understanding of previous work.
ByteDance Has No Surplus Funds Left? No More Forever Free GPT-4; Subscription Pricing is Unsuitable for AI Products! Various Pricing Strategies to Make Users Pay | ShowMeAI Daily
This article, published by the ShowMeAI Research Center, mainly explores the pricing strategies and business models of AI applications. The article starts with Coze's pricing plan, analyzing the high cost and complexity of AI product pricing. It introduces nine business models, including SaaS, transactional, and two-sided markets, detailing their key metrics and development points based on YC partners' insights. The article studies the pricing strategies of 40 popular AI applications and finds that most still use traditional SaaS subscription models, but innovative pricing based on outcomes and demand has also emerged. Finally, the article provides various ideas for monetizing with AI side projects, such as AI-generated scripted videos, AI-generated image creation, and AI-generated copywriting, along with specific operational suggestions and precautions.
So, are these AI products all dead? Entrepreneurship is a high-stakes game; Independent developers' marketing strategies; Google has shut down more than 300 projects | ShowMeAI
This article explores the phenomenon of failure in AI and technology entrepreneurship, mainly from four aspects: Firstly, it introduces the Google Graveyard, an open source project that records more than 300 projects that Google has discontinued, demonstrating that even top technology companies face numerous failures. Secondly, CB Insights's report analyzed 483 startups and pointed out the 12 main reasons for entrepreneurial failure. Thirdly, DANG!, an AI tool aggregation website, established an AI Graveyard to record 738 AI projects that were shut down and analyzed the main reasons for their failure. Finally, the article introduces James Steinberg, a serial entrepreneur, who publicly disclosed the progress and data of nearly 30 startup projects and summarized his marketing experiences. The article also cites Erik Bernhardsson's 'Simple Sabotage for Software' as a negative teaching material to show how to avoid similar failures.
Why is AI Entrepreneurship Still Worth Pursuing?
This article, published by Founder Park Research Center, is based on Zhang Peng's speech at AGI Playground 2024. It reviews the development of the internet and mobile internet, highlighting the relationship between economic value increment and the total amount of information and its flow efficiency. Using ByteDance as an example, the article explains the company's contributions in key technologies such as intelligent recommendation engines. The article emphasizes that the emergence of Artificial General Intelligence (AGI) will fundamentally change intelligent supply. This shift could potentially enable the true realization of mass customization. The article suggests that entrepreneurs should leverage AI technology to transform supply, not just optimize connectivity. Product development needs to incorporate new variables, such as model capability and data flow design. Entrepreneurs should explore AI products that users truly desire and choose markets with potential and growth space in the new era.