BestBlogs.dev Highlights Issue #21
Subscribe Now👋 Dear friends, welcome to this week's curated article selection from BestBlogs.dev!
🚀 This week, the AI field has once again witnessed groundbreaking innovations across various domains. OpenAI introduced real-time multimodal API and prompt caching features, significantly boosting development efficiency. Meta's MovieGen video generation model showcased AI's potential in producing high-quality, long-form videos. In academia, Shanghai Jiao Tong University's GAIR research group made significant strides in replicating OpenAI's o1 model, introducing the novel "journey learning" technique. On the development front, updates to frameworks like Spring AI and Gradio 5 have empowered developers with more robust tools. At the application level, OpenAI's canvas interface and Kimi's AI deep search functionality demonstrated AI's immense potential in enhancing productivity. Hardware innovations are equally noteworthy, from ByteDance's AI-powered earphones Ola Friend to AMD's upcoming next-generation AI chips, signaling AI's transition from cloud to edge computing. Lastly, the 2024 Nobel Prizes in Physics awarded to Geoffrey Hinton and John Hopfield, along with DeepMind's related research winning the Chemistry Prize, underscore AI's growing importance in the scientific community. Join us as we explore these exciting AI developments!
💫 Highlights of the Week
- OpenAI releases real-time multimodal API and prompt caching features, significantly improving development efficiency and reducing costs
- Meta unveils MovieGen video generation model, capable of producing high-quality long-form videos with audio
- Shanghai Jiao Tong University's GAIR research group makes significant progress in replicating OpenAI's o1 model, proposing "journey learning" technology
- LLaMA-Omni model achieves breakthrough in low-latency, high-quality voice interaction, with open-sourced code and model
- Development frameworks like Spring AI and Gradio 5 introduce new features, streamlining AI application development
- OpenAI launches canvas interface, substantially enhancing writing and programming capabilities
- Kimi debuts AI deep search functionality, further improving intelligent search experience
- ByteDance introduces its first AI-powered earphones, Ola Friend, showcasing new directions in AI hardware
- Geoffrey Hinton and John Hopfield awarded the 2024 Nobel Prize in Physics, with DeepMind's related research winning the Chemistry Prize
- AMD announces next-generation AI chips, competing with NVIDIA's Blackwell series, slated for release in 2025
Eager to dive deeper into these fascinating AI developments? Click to read the full articles and explore more exciting AI innovations!
Table of Contents
- OpenAI DevDay: Real-time Multimodal API, Prompt Caching, Vision Fine-tuning, and More for Developers
- Meta's Movie Gen Emerges: Zuckerberg Unveils 16-Second High-Definition Video, 92-Page Paper Reveals Technical Details, Llama 3 Architecture Plays a Key Role
- Meta Delivers Another Blow to OpenAI with the Stunning Video Generation Model Movie Gen, Featuring Dubbing and Editing Capabilities
- Shanghai Jiao Tong University Releases First Progress Report on OpenAI o1 Reproduction Project, Full of Insights
- A Deep Dive into LLM Reasoning: Professor Wang Jun of UCL Explains OpenAI o1's Methods
- Noam Brown's Speech Unveils the Powerful Reasoning Abilities of o1 and Explores the Research Framework of AI Reasoning
- Inside Scoop: 20 Truths About o1
- 280-page PDF: Comprehensive Evaluation of OpenAI o1, Leetcode Coding Challenges Accuracy is Surprisingly High
- Important Things Should Be Repeated Twice! Prompt "Repetition Mechanism", Significantly Improves LLM Reasoning Ability
- Sebastian Raschka's Latest Blog: Building Llama 3.2 from Scratch with Llama 2
- LLaMA-Omni: Open-Source, Low-Latency, High-Quality Speech Interaction
- Google Develops Voice Transfer AI for Restoring Voices
- Concepts: Types of Deep Learning
- Exploration of AI Architecture Based on Cognitive Theory
- Llama 3 in Action: Deployment Strategies and Advanced Feature Applications
- Launching Long-Term Memory Support in LangGraph
- LlamaIndex for RAG on Google Cloud
- Can Long-Context Replace Retrieval-Augmented Generation (RAG)?
- Demystifying Prompt Compression Technology
- Supercharging Your AI Applications with Spring AI Advisors
- JD.com's Large Language Model Revolutionizes E-commerce Search and Recommendation Technology: Challenges, Practices, and Future Trends
- Exploration and Practice of Global User Modeling in Meituan Homepage Recommendation
- AI Integration for Java: To the Future, From the Past
- Welcome, Gradio 5
- How to Start Building Projects with LLMs
- 5 tips and tricks when using GitHub Copilot Workspace
- OpenAI Launches 'canvas': A New Interactive Interface for ChatGPT, Empowering Writing and Programming
- Lex Fridman Interviews the Cursor Team: An AI Programming Product Aiming for Market Fit and to Replace Copilot
- Kimi Embraces AI Search, Defining Its Product Form, Exploring Productivity in Chat
- A Comprehensive Exploration: Breakthrough Directions and Potential Futures of AI Hardware
- In-depth | Conversation with Stability Founder: Video Technology Enters Engineering Phase, 2025 Will Be the Year of the Agent
- One Year Later: How Are the Text-to-Image Products That Made It to the First a16z List Doing?
- First Look | I Wore the 'AI-Powered Headphones' for a Week and Found the New Answer for AI Hardware
- Zhipu AI Unveils a Powerful Tool: AI Search Experience Based on Chain of Thought
- The Underlying Logic of Excellent Products
- Market Landscape of AI Companions
- Exploring the Virtual Digital Human Industry: Current Status, Challenges, and Future
- Must-Read for AI Enthusiasts! Anthropic CEO's Long Essay - Predicting a Positive Future for Superintelligence
- AMD Unveils Powerful AI Chip, Rivaling NVIDIA's Blackwell, Set for 2025 Launch
- $650 Million! AI Agents' Largest Acquisition: Jake Keller Interview on Vertical AI Agents as the New Opportunity to Become a $10 Billion Unicorn, Decided in Just 48 Hours
- Tesla's Robotaxi Unveiled: Musk's Vision for the Future of Transportation (Full Text)
- Geoffrey Hinton and John Hopfield Win 2024 Nobel Prize in Physics
- Nobel Prize in Chemistry Awarded to DeepMind: How AI Revolutionized Protein Research?
- The AI Image Revolution: Just Getting Started
- Sequoia Capital Interviews NVIDIA's Jim Fan: Building AI Brains for Humanoid Robots, and Beyond
- Express Delivery - 39 US AI Startups Raised Over $100 Million in 2024: Complete List
- Tencent Research Institute Dialogue with Former OpenAI Researcher: Why Greatness Cannot Be Planned? | Leave a Comment to Win Books
- The Dawn of Generative AI [Translation]
- YC Demo Day Project Overview: Four New Trends in AI Startups, 22 AI Startups to Watch
- A Short Summary of Chinese AI Global Expansion
OpenAI DevDay: Real-time Multimodal API, Prompt Caching, Vision Fine-tuning, and More for Developers
OpenAI's 2024 DevDay highlighted five major innovations focused on enhancing developer capabilities and lowering AI application costs. These advancements include a Real-time API, Prompt Caching, Model Distillation, Vision Fine-tuning, and a new framework for prompt engineering. The Real-time API enables developers to create low-latency voice-to-voice experiences, while Prompt Caching reduces costs and latency by storing commonly used contexts. Model Distillation allows smaller companies to leverage the power of large AI models without the high computational costs, bridging the gap between resource-intensive systems and more accessible, yet less powerful ones. Vision Fine-tuning enhances visual understanding by combining images and text, potentially revolutionizing fields like autonomous driving and medical imaging. The new framework for prompt engineering simplifies the development process by improving prompt structures and structured outputs. These updates not only demonstrate OpenAI's technological progress but also signal a strategic shift towards building a robust developer ecosystem. By increasing efficiency and cost-effectiveness, OpenAI aims to maintain a competitive edge while addressing concerns about resource intensity and environmental impact.
Meta's Movie Gen Emerges: Zuckerberg Unveils 16-Second High-Definition Video, 92-Page Paper Reveals Technical Details, Llama 3 Architecture Plays a Key Role
Meta's latest release of the Movie Gen model marks a significant leap forward in AI video generation technology. Movie Gen is a 30B parameter Transformer model capable of generating 1080p, 16-second, 16 frames per second high-definition videos from a single text prompt, while also supporting sound generation and video editing. Movie Gen also introduces a 13B parameter audio model capable of generating high-fidelity audio synchronized with the video. Meta has published a 92-page paper detailing the architecture, training methods, and experimental results of Movie Gen. The paper mentions that the Movie Gen video model follows the Transformer design and draws on the Llama 3 architecture, significantly enhancing the precision and detail of video generation through the introduction of 'Flow Matching' technology. This technique, compared to traditional diffusion models, offers significant advantages in training efficiency and generation quality. While the product is expected to be officially released to the public next year, this release has already garnered widespread attention and is considered a milestone in the field of AI video generation. However, Movie Gen may face practical issues such as high computational resource requirements and real-time challenges during application.
Meta Delivers Another Blow to OpenAI with the Stunning Video Generation Model Movie Gen, Featuring Dubbing and Editing Capabilities

Meta has unveiled its groundbreaking generative AI research, Movie Gen, on its blog, demonstrating remarkable capabilities in video generation. Movie Gen can generate high-quality videos and audio based on text prompts, edit existing videos, and even create videos from images. Meta emphasizes that Movie Gen is designed to provide filmmakers and video creators with tools that enhance their creative potential. The article delves into the various features and technical aspects of Movie Gen, including video generation, personalized video creation, precise video editing, and audio generation. Movie Gen utilizes a 30B parameter Transformer model, capable of generating high-quality videos up to 16 seconds long, and excels in object motion, subject-object interaction, and camera movement. Furthermore, Movie Gen supports personalized video generation, allowing users to provide character images and text prompts to create videos featuring specific individuals. In video editing, Movie Gen enables precise pixel-level editing, supporting the addition, removal, and replacement of elements, as well as advanced editing features like background and style modifications. For audio generation, Movie Gen can produce high-quality audio based on video and optional text prompts, including ambient sounds, sound effects, and background music. Meta trained Movie Gen using a large number of H100 GPUs and a multi-stage training method, ensuring the model outperforms similar models in the industry across various tasks. The article concludes by highlighting that Movie Gen's release positions Meta as a formidable competitor in the video generation landscape and has sparked discussions regarding its potential free release.
Shanghai Jiao Tong University Releases First Progress Report on OpenAI o1 Reproduction Project, Full of Insights

The GAIR research group at Shanghai Jiao Tong University (SJTU), in the process of reproducing the OpenAI o1 project, proposed the innovative 'Journey Learning' technology, which outperformed traditional supervised learning by more than 8% on complex math problems with 327 training samples, achieving a relative performance improvement of over 20%. The report emphasizes the importance of transparently documenting and sharing the exploration process, advocating for a new AI research paradigm that focuses on fundamental issues and scientific discoveries. The team detailed the research progress of 'Extended Thinking', including its working principles, construction methods, reward model design, and steps to derive 'Extended Thinking' from the reasoning tree. 'Extended Thinking' is generated by traversing the reasoning tree using Depth-First Search (DFS) and enhanced for coherence using GPT-4o, with a visualization platform built to evaluate the model. The model is trained using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), exploring effective strategies for human-AI collaborative annotation. The report also outlines key future exploration directions, including the synthesis of 'Extended Thinking', experimental laws of 'Extended Thinking' expansion, fine-grained evaluation, and introduces the 'Walnut Initiative', aiming to drive AI from an information processing tool to a system with deep thinking capabilities, ultimately realizing an AI-driven research paradigm.
A Deep Dive into LLM Reasoning: Professor Wang Jun of UCL Explains OpenAI o1's Methods

This article explores how OpenAI's o1 model significantly enhances the reasoning capabilities of Large Language Models (LLM) through Reinforcement Learning and Chain-of-Thought Reasoning. The o1 model engages in in-depth reasoning before generating responses, significantly improving performance in scientific, programming, and mathematical tasks. Professor Wang Jun of UCL will release an open-source framework at the RLChina 2024 conference to support the further development of these technologies. The article further explores key technologies in LLM reasoning, such as Markov Decision Process (MDP), Process Reward Model (PRM), Self-Enhancing Training, and Policy Iteration. Additionally, it introduces the application of GRPO Strategy and Monte Carlo Tree Search (MCTS) in reasoning. The article concludes with a summary of multiple research papers on LLM reasoning, covering self-learning paradigms, data collection, and understanding and system-level improvements in LLM reasoning mechanisms.
Noam Brown's Speech Unveils the Powerful Reasoning Abilities of o1 and Explores the Research Framework of AI Reasoning

Noam Brown's speech provides a detailed account of his research journey in the field of AI reasoning, particularly his breakthroughs in games like poker, Go, and Diplomacy. He emphasizes the critical role of search and planning algorithms in boosting AI performance and demonstrates through specific examples how these algorithms significantly improve AI's performance. Brown also discusses the application of these technologies in natural language processing, such as the success of the Cicero system in Diplomacy. Additionally, he envisions future directions for AI development, particularly how increasing reasoning computation can lead to more powerful AI models. The speech also mentions Richard Sutton's 'bitter lesson,' emphasizing the importance of general methods utilizing computational power in AI research.
Inside Scoop: 20 Truths About o1
This article provides a detailed introduction to the training methods, reasoning process, and application performance of the o1 Model in multiple fields. The o1 Model employs large-scale reinforcement learning algorithms and chain-of-thought prompting, enabling it to demonstrate higher efficiency and quality in reasoning and problem-solving. Compared to previous models, o1 can handle more complex problems and generate a long internal chain of thought before responding to users, allowing for deeper and more comprehensive analysis. Additionally, o1 is more flexible and intelligent in its security mechanisms, capable of understanding the nuances of security policies and making more nuanced judgments in complex situations. o1 Mini, as a smaller, faster, and cheaper model, performs similarly to the full version of o1 in STEM tasks, showcasing its high performance in specific tasks. The article also discusses o1's performance in creative fields, where it is not yet as prominent as in STEM, but researchers are exploring how to apply o1's powerful reasoning capabilities to more creative tasks. The improvements in o1 primarily come from new algorithms and training methods.
280-page PDF: Comprehensive Evaluation of OpenAI o1, Leetcode Coding Challenges Accuracy is Surprisingly High

This article details the systematic evaluation of OpenAI's o1-preview model by institutions such as the University of Alberta, Canada, covering various complex reasoning tasks including programming challenges, radiology report generation, high school math reasoning, natural language reasoning, chip design, quantitative investment, and social media analysis. The evaluation results show that o1-preview performs exceptionally well in these tasks, particularly in programming challenges with a success rate of 83.3%, surpassing many human experts. It outperforms other models in radiology report generation and achieves 100% accuracy in high school math reasoning tasks, providing detailed problem-solving steps. While o1-preview occasionally stumbles on simple problems and struggles with highly specialized concepts, its overall performance indicates significant progress towards Artificial General Intelligence (AGI). The evaluation highlights the current strengths and limitations of o1-preview, pointing out key areas for future development, such as multimodal integration, domain-specific validation, and ethical considerations in practical applications. These findings provide valuable insights into the potential of large language models across numerous fields and pave the way for further development in AI research and application.
Important Things Should Be Repeated Twice! Prompt "Repetition Mechanism", Significantly Improves LLM Reasoning Ability
This article explores how simple prompt repetition, referred to as the 'Repetition Mechanism' (RE2), can significantly enhance the reasoning capabilities of large language models (LLMs). While LLMs excel in many tasks, they often struggle with complex reasoning problems compared to humans. Experiments demonstrate that repeating the input question can improve a model's understanding and reasoning abilities. Specifically, RE2 allows the model to access the full context during the second pass of processing the question, enabling bidirectional understanding. Experimental results consistently show performance improvements across 112 experiments on 14 datasets, regardless of whether the models are instruction-tuned (like ChatGPT) or non-tuned (like Llama). Furthermore, RE2 can be combined with other prompting techniques, such as CoT (Let's think step by step) and self-consistency methods, to further enhance model performance on complex tasks. The article delves into the implementation principles, experimental setup, and results of RE2, showcasing its versatility and effectiveness across various tasks and models.
Sebastian Raschka's Latest Blog: Building Llama 3.2 from Scratch with Llama 2
Sebastian Raschka's latest blog post details the process of transitioning Meta's Llama 2 architecture model to Llama 3, Llama 3.1, and Llama 3.2. The article begins by introducing the new features of Llama 3.2, released at Meta Connect 2024, including lightweight models designed for edge and mobile devices, capable of multilingual text generation and tool calling. The article then delves into the improvements made to Llama 3's RoPE (Rotary Position Encoding), such as increasing the context length and adjusting the theta base value to enhance model performance. Next, it explains how to replace Multi-Head Attention (MHA) with Grouped Query Attention (GQA) for improved computational and parameter efficiency, providing code examples illustrating GQA implementation details. Additionally, the article outlines how to build Llama 3.2's multi-head attention mechanism using Llama 2, highlighting key steps like RoPE application, attention score calculation, and context vector generation, and offering example code for parameter savings. Finally, the article discusses the configuration parameters and memory requirements of the Llama 3 8B model, demonstrating how to calculate model memory usage and transfer the model to different hardware devices through code examples.
LLaMA-Omni: Open-Source, Low-Latency, High-Quality Speech Interaction
LLaMA-Omni, developed by the NLP group at the Institute of Computing Technology, Chinese Academy of Sciences, is an innovative speech interaction model designed to address the need for low latency and high accuracy in voice interfaces. It integrates a pre-trained speech encoder, speech adapter module, large language model (LLM), and streaming speech decoder, enabling direct generation of text and speech responses from voice commands, eliminating the intermediate step of text-to-speech conversion in traditional methods. Built upon the Llama-3.1-8B-Instruct model and trained using the "InstructS2S-200K" dataset containing 200,000 voice commands and their corresponding speech responses, LLaMA-Omni delivers superior responses in terms of content and style, with an impressive response latency of just 226 milliseconds. Its training efficiency is remarkably high, completing training in less than 3 days on 4 GPUs, paving the way for future efficient development of speech language models. The open-source code and model are available on GitHub and ModelScope, facilitating further research and application by developers. While LLaMA-Omni demonstrates significant advantages in real-time speech interaction, potential challenges in practical deployment need to be addressed.
Google Develops Voice Transfer AI for Restoring Voices
/filters:no_upscale()/news/2024/10/google-voice-transfer-ai/en/resources/1vt-architecture-1726313210046.png)
Google Research has introduced a groundbreaking zero-shot voice transfer (VT) model designed to customize text-to-speech (TTS) systems with a specific person's voice, particularly beneficial for individuals who have lost their voice due to conditions such as Parkinson's disease or ALS. The model operates in both few-shot and zero-shot modes, requiring only a few seconds of reference speech audio to replicate a voice, which is crucial for those who may not have pre-recorded multiple audio samples. It supports cross-lingual capabilities, producing speech in languages different from the reference speaker's native language. Google conducted experiments showing that 76% of human judges could not distinguish between real and generated speech. The VT model is based on a TTS system trained on diverse multilingual data, supporting over 100 languages. Ethical concerns about misuse are addressed with audio watermarking. The model's practical applications in speech therapy and voice restoration are particularly noteworthy, highlighting its innovative impact on AI-driven solutions for communication challenges.
Concepts: Types of Deep Learning

The article introduces a series of flashcards designed to educate readers about various types of deep learning. It is part of a broader initiative to make machine learning concepts accessible to a wide audience, including children. The author, a mother of five, provides explanations tailored for both adults and a younger audience, aiming to simplify complex concepts. The article also mentions the recent awarding of Nobel Prizes in Chemistry and Physics, which were influenced by deep learning advancements. This context underscores the importance and impact of deep learning in contemporary scientific achievements. The flashcards are accompanied by visual aids and are available in a downloadable PDF format for premium subscribers. The article encourages feedback and collaboration to improve the educational content.
Exploration of AI Architecture Based on Cognitive Theory
This article examines the design and optimization of AI architectures from a cognitive theory perspective. It introduces the Sibyl Experimental Project, built upon cognitive theory, which demonstrated outstanding performance in the GAIA Evaluation, showcasing the theory's extensibility and the metrics' generalizability. The article then compares Sibyl and ChatGPT's performance in handling complex tasks, revealing Sibyl's superior reasoning capabilities and context management. It delves into the core capabilities of agents based on Large Language Models (LLMs) in planning, memory, and tool use, highlighting the limitations of current Agent systems in theoretical guidance and complex thinking. The article further explores the application of dual-process theory and global workspace theory in AI systems, along with the design philosophy of the Sibyl architecture, emphasizing the pivotal role of cognitive science in enhancing AI system performance. Finally, it proposes evaluation methods for AI systems, emphasizing the distinction between crystallized intelligence and fluid intelligence, and discusses the significance of reasoning capabilities and agency in AI systems.
Llama 3 in Action: Deployment Strategies and Advanced Feature Applications
This article, part of a series on practical generative AI applications, details the deployment strategies and advanced feature applications of Meta's released Llama 3 Large Language Model. It begins by tracing the development of the Llama series, from its initial LLaMA version to the current Llama 3, highlighting the model's architectural evolution and enhancements. Llama 3 includes models with 800 million and 7 billion parameters, both open-source and freely available for commercial use. The article delves into the subtle architectural differences between Llama 3 and its predecessors, particularly in embedding technology and data processing optimizations. By comparing the 'config.json' file in the HuggingFace repository, the article demonstrates the consistency of the model structure and the differences in parameter configuration. Data engineering plays a crucial role in enhancing Llama 3's performance. The article details Meta's data processing strategies during the pre-training and fine-tuning phases, including optimizations in data scale, quality, and data blending strategies. These strategies have enabled Llama 3 to perform exceptionally well in multiple benchmark tests, particularly in the 8B and 70B models, outperforming similar open-weight models. In terms of deployment in production environments, the article provides detailed guidance, including deployment steps on AWS EC2 instances, computational resource requirements, and inference speed optimizations. Additionally, the article introduces methods for model inference and deployment using tools like the vLLM library and Amazon SageMaker JumpStart. Finally, the article showcases various practical applications of Llama 3, including larger context windows, offline Retrieval-Augmented Generation (RAG), fine-tuning for vertical domains, and function calling and tool usage. These applications demonstrate Llama 3's flexibility and powerful performance in different fields.
Launching Long-Term Memory Support in LangGraph
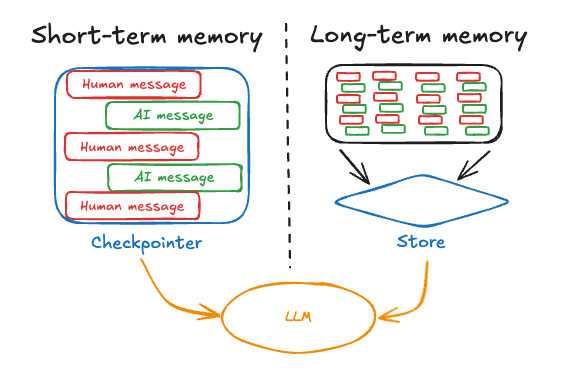
The article announces the introduction of long-term memory support in LangGraph, a feature that allows AI agents to store and recall information across multiple conversations. This enhancement enables agents to learn from feedback and adapt to user preferences, addressing the limitation of current AI applications that forget information between interactions. The memory support is implemented as a persistent document store, providing basic primitives like put, get, and search operations. It also offers flexible namespacing and content-based filtering, making it adaptable to various application needs. The feature is available in both Python and JavaScript versions of LangGraph and is enabled by default for all LangGraph Cloud & Studio users. The article provides resources for deeper understanding and practical implementation, including conceptual videos, guides, and templates for integrating long-term memory into LangGraph projects. Additionally, the potential impact on enhancing user experience and its market value is emphasized.
LlamaIndex for RAG on Google Cloud

The article introduces Retrieval Augmented Generation (RAG) and its importance in building Large Language Model (LLM)-powered applications, emphasizing the need for developers to experiment with various retrieval techniques. It provides a practical guide on using LlamaIndex, Streamlit, RAGAS, and Google Cloud's Gemini models for rapid prototyping and evaluation of RAG solutions. The article breaks down the RAG workflow into four steps: indexing and storage, retrieval, node post-processing, and response synthesis, detailing how LlamaIndex simplifies these processes. Google Cloud's Document AI Layout Parser is highlighted as a solution for document processing. Advanced retrieval techniques like auto-merging retrieval are discussed, leveraging hierarchical indexing for improved accuracy. The article concludes by examining retrieval processes using LlamaIndex's Retriever module and auto-merging retriever, enhancing retrieval accuracy. It also compares LlamaIndex with other RAG tools, emphasizing its unique advantages and discusses performance optimization strategies in the Google Cloud environment.
Can Long-Context Replace Retrieval-Augmented Generation (RAG)?
The article traces the evolution of Large Language Models (LLMs), from their early stages with limited context lengths and knowledge inconsistencies to the current mainstream models like GPT-4o and Claude-3.5, which support long contexts of up to 128K or even 1M tokens. As LLM context lengths expand, the necessity of Retrieval-Augmented Generation (RAG) has been questioned. Previous research indicated that long contexts consistently outperformed RAG in terms of answer quality. However, NVIDIA researchers discovered through experiments that the order of retrieved chunks within the LLM context significantly impacts answer quality. Traditional RAG arranges retrieved chunks by relevance in descending order, while OP-RAG, which preserves the original text order of retrieved chunks, demonstrably enhances answer quality. Experiments on the En.QA dataset reveal that the OP-RAG method (using the Llama3.1-70B model) achieved an F1-score of 44.43 with only 16K retrieved tokens, surpassing the 34.32 score of Llama3.1-70B without RAG even when fully utilizing a 128K context. Moreover, OP-RAG excels in resource utilization efficiency, achieving superior results with fewer tokens. The article further examines the influence of context length and the number of retrieved chunks on OP-RAG performance, highlighting the trade-off between retrieving more context to improve recall and limiting interference to maintain accuracy. Finally, the article acknowledges potential challenges for OP-RAG in practical applications, including its adaptability across different scenarios and its ability to distinguish irrelevant information.
Demystifying Prompt Compression Technology

This article explores the issues of inference costs and time extension caused by prompt length in applications of large language models (LLMs). Zhuoshi Technology's proposed Chinese Prompt Compression Technology significantly reduces inference costs and time by defining long prompt structures, aligning the distribution of small language models with large language models, implementing multi-level compression strategies, and preserving specialized vocabulary. In multi-document search and question-and-answer systems, this technology significantly improves response speed and accuracy, especially suitable for applications in vertical domains.
Supercharging Your AI Applications with Spring AI Advisors
In the rapidly evolving field of artificial intelligence, developers are constantly looking for ways to improve their AI applications. Spring AI, a Java framework designed for building AI-powered applications, has introduced a powerful feature called Spring AI Advisors. These Advisors are components that intercept and potentially modify the flow of chat-completion requests and responses in AI applications, making them more modular, portable, and easier to maintain. The core of Spring AI Advisors is the AroundAdvisor, which allows developers to dynamically transform or utilize information within these interactions. The main benefits of using Advisors include encapsulating recurring tasks, transforming data sent to Language Models (LLMs) and formatting responses, and creating reusable transformation components that work across various models and use cases. Developers can also implement their own custom Advisors using the Advisor API, which includes interfaces for non-streaming and streaming scenarios. Implementing Advisors enables AI applications to manage conversation history, improve model reasoning, and enhance overall application functionality. Best practices include keeping Advisors focused on specific tasks, using the advise-context for state sharing, and implementing both streaming and non-streaming versions of Advisors.
JD.com's Large Language Model Revolutionizes E-commerce Search and Recommendation Technology: Challenges, Practices, and Future Trends
This article delves into the challenges, practices, and future trends of JD.com's application of large language models (LLMs) in e-commerce search and recommendation technology. It begins by outlining the evolution of the e-commerce industry, highlighting the shift from traditional shelf-based e-commerce to a diversified model that incorporates content-driven e-commerce. This transformation underscores the profound impact of technological advancements on the retail sector. JD.com has comprehensively enhanced the user shopping experience by optimizing search algorithms, improving customer service quality, and perfecting the after-sales service system. The article then analyzes the evolution of e-commerce search technology, tracing its journey from text retrieval to the current era of LLMs, and envisioning the future emergence of AGI shopping assistants. LLMs have demonstrated remarkable capabilities in e-commerce scenarios, exhibiting strong language understanding, knowledge summarization, transfer learning, and logical reasoning abilities, significantly enhancing the intelligence level of search and recommendation systems. The article further explores the application challenges of LLMs in e-commerce, including e-commerce knowledge understanding, effectiveness and personalization, timeliness, cost and speed, and security issues. It proposes a set of AIGC architecture solutions based on LLMs, aiming to address these practical challenges. JD.com has implemented key technological advancements, including incremental learning frameworks, base LLMs, parameter expansion, long context expansion, and domain alignment, to enhance model performance. Simultaneously, the company prioritizes model security and evaluation systems. Finally, the article discusses the technological and product form innovations of the next-generation AI e-commerce search, emphasizing how LLMs and AGI technology-driven digital virtual assistants can enhance user experience and address the pain points of traditional e-commerce search.
Exploration and Practice of Global User Modeling in Meituan Homepage Recommendation

This article, written by the Meituan Technology Team, delves into the application and practice of global user modeling in Meituan homepage recommendation. It first emphasizes the necessity of global user modeling, stating that integrating user behavior data from multiple platforms and applications can significantly improve the accuracy and diversity of the recommendation system. However, Meituan homepage recommendation faces challenges such as sparse user behavior and data distribution differences, requiring refined data integration and model training strategies. Spatio-temporal scenario information is crucial for recommendation results, with significant differences in transferability across different business scenarios. The Meituan Technology Team optimized the recall and ranking models through a multi-stage iterative strategy, introducing global signals to enhance user interest modeling capabilities and business metrics. The Explicit Interest Transfer Cross-Domain Recommendation Framework (EXIT) was proposed, addressing negative transfer issues in cross-domain recommendations by assigning different types of supervisory signals with hierarchical weights, thereby improving homepage recommendation effectiveness. Global Full-Chain Unified Modeling resolved issues such as incomplete external domain signals, lack of global features, and insufficient chain consistency, further enhancing recommendation effectiveness through unified sample construction and global perception enhancement modeling. In the future, the Meituan Technology Team plans to introduce external domain click signals to enrich the data source and explore generative recommendation paradigms.
AI Integration for Java: To the Future, From the Past
The article delves into the integration of AI into Java development, featuring insights from experts at JetBrains, Microsoft, Morgan Stanley, and Moderne. It discusses the challenges and opportunities of applying AI in software development, particularly in enhancing development tools and automating code changes. Real-world examples from Azure OpenAI service, Mercedes Benz, and American Airlines demonstrate AI's potential to transform user experiences and operational efficiency. Key libraries like LangChain4j and Spring AI are highlighted, emphasizing that AI integration is not limited to Python developers. The article further explores how AI tools like OpenRewrite and GitHub Copilot can significantly enhance developer productivity by automating routine tasks and reducing technical debt. It also discusses the role of generative AI in large-scale code refactoring and the importance of testing during such processes. Overall, the article provides a comprehensive overview of the current state and future potential of AI in Java development.
Welcome, Gradio 5

The article announces the stable release of Gradio 5, a major update aimed at making it easier for developers to build production-ready machine learning web applications. Gradio 5 addresses several pain points identified by developers, such as slow loading times, outdated design, and lack of real-time capabilities. Key features include server-side rendering (SSR) for faster loading, a refreshed modern design with new themes, low-latency streaming support, and an experimental AI Playground for generating and modifying Gradio apps. The release also focuses on improving web security and maintaining a simple, intuitive API. Future developments are anticipated, such as multi-page apps, mobile support, and richer media components, enhancing Gradio's potential to revolutionize ML app development.
How to Start Building Projects with LLMs
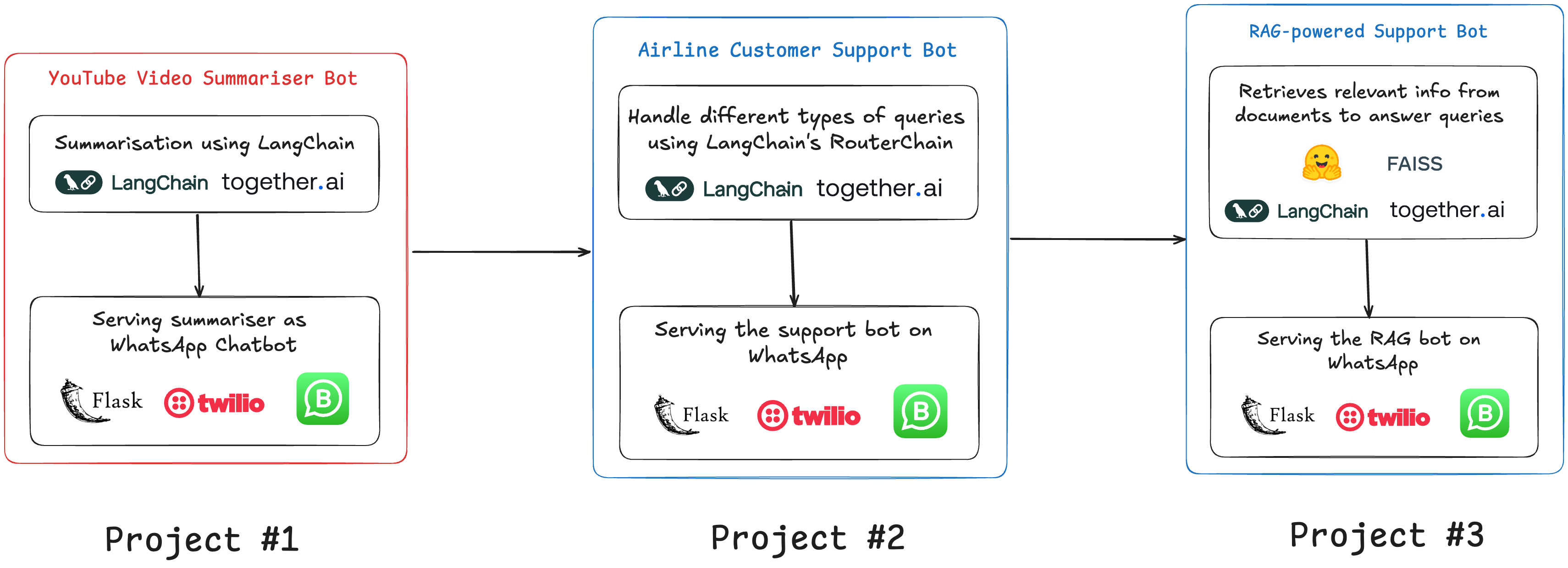
The article is aimed at aspiring AI professionals who want to become LLM engineers. It highlights the importance of project-based learning as the best way to master LLM concepts. The author offers a detailed roadmap for starting LLM projects, beginning with a YouTube video summarizer using Python packages like langchain-together and youtube-transcript-api. The project involves setting up an LLM with the Llama 3.1 model from Together AI, processing YouTube transcripts, and deploying the summarizer on WhatsApp using Flask and Twilio. The article also previews two more complex projects: a multi-purpose customer service bot and a RAG-powered support bot, both featured in a course on building LLM-powered WhatsApp chatbots, designed to develop industry-relevant skills.
5 tips and tricks when using GitHub Copilot Workspace

The article, published on The GitHub Blog, offers a comprehensive guide on optimizing the use of GitHub Copilot Workspace, an AI-driven development environment. It begins by recapping the functionality of Copilot Workspace, which assists developers in completing coding tasks by providing iterative suggestions and allowing for direct code editing. The article then transitions into sharing five key tips gathered from both the GitHub Next team and the developer community. These tips include being specific about task goals and providing additional context, decomposing larger tasks into smaller, manageable parts, iteratively reviewing and refining suggestions, directly editing code within the workspace, and conducting builds and tests within the environment. The article concludes by encouraging readers to explore more about Copilot Workspace through GitHub Universe sessions, Discord community interactions, and signing up for the technical preview, emphasizing community involvement and ongoing learning.
OpenAI Launches 'canvas': A New Interactive Interface for ChatGPT, Empowering Writing and Programming

OpenAI has recently unveiled 'canvas', a groundbreaking new interactive interface for ChatGPT, marking the first major visual update since its launch. 'canvas' aims to empower users in writing and programming projects by seamlessly integrating with ChatGPT, boosting both efficiency and output quality. This interface supports diverse output formats, including text files, code, web pages, and SVG. Users can highlight text or code, allowing ChatGPT to understand their requirements more precisely and execute corresponding modifications and optimizations. Powered by GPT-4o, 'canvas' is currently in its Beta testing phase, accessible only to ChatGPT Plus and team users. Enterprise and educational users will gain access next week, while free users will have to wait for the official release. OpenAI's research team has rigorously trained GPT-4o through extensive automated internal evaluations and innovative synthetic data generation techniques, enabling it to function as a creative partner, providing accurate feedback and suggestions. The introduction of 'canvas' represents a significant step forward for OpenAI in enhancing AI interaction experiences and application values. While 'canvas' offers a more intuitive user experience and productivity enhancements in practical applications, its compatibility with existing tools and potential challenges require careful consideration.
Lex Fridman Interviews the Cursor Team: An AI Programming Product Aiming for Market Fit and to Replace Copilot
This article features an interview with the Cursor team by Lex Fridman, exploring the innovative aspects and future trajectory of their AI programming tool. The Cursor team believes that large models will fundamentally change the way software is developed. They have created Cursor, aiming to build a more useful AI programming tool rather than simply a plugin for existing editors. The team emphasizes that staying ahead and rapid development are crucial for competing with Github Copilot, predicting that sparse models (Mixture of Experts, or MoE) will be the optimal architecture for handling longer contexts. Cursor addresses contextual challenges through expert models (MoE), enhancing programming efficiency and user experience by not only predicting the next code action but also enabling cross-file editing. The interview also delves into the performance of AI programming tools, model selection, the limitations of benchmark testing, and the application of agents in programming, highlighting the advantages of custom models for specific tasks. The article further examines the challenges faced by AI programming products during expansion and optimization, particularly code synchronization and local model performance issues, and explores the potential of homomorphic encryption technology to safeguard data privacy. Finally, the team discusses the future direction of AI programming products, focusing on context processing, model optimization, synthetic data, and the application of Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF), as well as the anticipated changes in the future of programming.
Kimi Embraces AI Search, Defining Its Product Form, Exploring Productivity in Chat
Kimi's recent release of an AI deep search feature further clarifies its product form. The article explores the development trend of AI product forms, particularly how OpenAI integrates models as product functions (Model-as-a-Feature) and incorporates them into ChatGPT. This approach not only enhances the practicality of the models but also improves user experience. Kimi founder, Yang Zhilin, emphasizes the importance of AI products as entry points, capable of handling any user questions or tasks. The article then details the new features of the Kimi Exploration Edition, including autonomous planning strategies, large-scale information retrieval, and instant reflection on search results, aimed at solving complex problems. The Kimi Exploration Edition primarily targets knowledge workers and college students, aiming to enhance their productivity. The article showcases the advantages of the Kimi Exploration Edition in handling complex problems, such as solving logical reasoning questions, and highlights its applications and growth in productivity scenarios.
A Comprehensive Exploration: Breakthrough Directions and Potential Futures of AI Hardware
This article explores the future development directions and application prospects of AI hardware from multiple perspectives. Firstly, it emphasizes the core role of software-driven innovation in the development of AI hardware, particularly the advancement of Large AI Models. These models infuse hardware with intelligence and anthropomorphism, acting as a magic touch that breathes life into it. Next, it analyzes the three-layer architecture of AI hardware, including multimodal signal input, model processing and computation, and interaction methods. Smartphones occupy the core value position in the computing center of this architecture. The article then proposes LUI (Language User Interface) as a potential next-generation interaction method, despite its limitations in information density. While LUI has advantages on the input side, it is currently only suitable for targeted single-point tasks due to its limitations in information density on the output side. Subsequently, the article discusses the prudent route of integrating AI technology into existing hardware categories, emphasizing the continued importance of smartphones as the core ecosystem position and the potential of wearable devices as sensors. Smart glasses, as an emerging category, are considered a significant direction for future development, with advantages such as high information density, first-person POV (Point of View), and large innovation space. However, current technical limitations hinder their widespread application. The article also explores the application and development trends of AI hardware in areas such as companion robots and XR devices (e.g., VR and AR), analyzing the market response, technical challenges, and future prospects of different products. Finally, the article discusses the development trends and challenges in the field of embodied intelligence, including the application of AI content generation technology in VR and AR, the investment boom in embodied intelligence and its technical difficulties, and the importance of hardware selection and adaptation. AI content generation technology will make 'world filters' possible, thereby deriving more gameplay and truly realizing the experience of augmented reality (AR). However, embodied intelligence faces technical challenges such as data collection costs and quality, hardware selection, and adaptation.
In-depth | Conversation with Stability Founder: Video Technology Enters Engineering Phase, 2025 Will Be the Year of the Agent
This article, through a conversation with Stability Founder Emad, delves into the current state and future trends of video technology. Emad believes that the technology required for high-quality video production is already in place but has not yet been fully integrated, requiring more breakthroughs in technical architecture. He predicts that 2025 will be the Year of the Agent, when models will be able to execute tasks and return results, rather than processing synchronously. Additionally, the article discusses the potential of model optimization, real-time generation, and personalized media in commercial applications, as well as the wide applications and career impacts of AI in healthcare, education, programming, and other fields. Emad emphasizes the importance of open models and open datasets, believing that this will drive further development in AI technology. He also predicts that future AI skill demands will shift towards management skills and model application capabilities, rather than traditional coding skills.
One Year Later: How Are the Text-to-Image Products That Made It to the First a16z List Doing?
The article begins by reviewing the 10 text-to-image products that appeared on last year's a16z Top 50 AI website list and analyzes their performance over the past year. While the 'survival rate' of these products reached 60%, the article notes that all listed products have experienced varying degrees of traffic decline. The article provides a detailed analysis of each product, including Midjourney, Leonardo.ai, PixAI, NightCafe, Playground, and others, discussing their technology curves, business models, feature updates, and market competition. The article also specifically mentions the transformation and commercial strategy adjustments of Stability.ai, the parent company of Stable Diffusion, amid financial difficulties. Finally, the article summarizes the market trends in the text-to-image sector, pointing out that with technological advancements and intensified market competition, the richness of product features, changes in interaction methods, scenario integration, and community building have become key competitive focuses.
First Look | I Wore the 'AI-Powered Headphones' for a Week and Found the New Answer for AI Hardware

This article delves into ByteDance's inaugural smart AI headphones, Ola Friend, which leverage large model technology within the headphone context to deliver personalized, round-the-clock companionship and immediate responses. Through real-world usage, the author illustrates Ola Friend's applications across various scenarios like travel, fitness, and learning. It acts as a travel companion providing real-time information and recommendations, a personal fitness coach crafting customized workout plans, and a language practice partner. The article highlights Ola Friend's natural voice interaction, rapid response times, and emphasis on comfort and battery life in its hardware design. Furthermore, Ola Friend demonstrates the capability of AI hardware to provide instant information and knowledge in daily life, enhancing user feelings of companionship and trust. The article concludes that the future trajectory of AI hardware should involve closer integration with users, offering more personalized and human-like services.
Zhipu AI Unveils a Powerful Tool: AI Search Experience Based on Chain of Thought
Zhipu AI recently unveiled an AI search agent based on Chain of Thought, a groundbreaking innovation that significantly enhances the experience and effectiveness of AI search. The article highlights the importance of Chain of Thought and model reasoning capabilities, as demonstrated by Open AI's release of O1 and O1 mini, particularly in fact-checking and complex problem-solving. Zhipu AI's new search agent goes beyond simply reading web content; it performs deep reasoning akin to Chain of Thought (COT), enabling it to tackle complex problems. Notably, this agent can read and summarize over 100 web pages simultaneously, achieving a speed 1‰ faster than human users. Its multi-level reasoning capabilities empower it to solve most challenging problems encountered in daily life. Furthermore, it seamlessly integrates with other Zhipu AI tools, such as Python, for comprehensive problem-solving. The article showcases the agent's impressive capabilities through various practical cases, including complex mathematical calculations, in-depth historical event analysis, stock market data analysis and visualization, and comparative analysis of industry markets. The article also emphasizes that the future of AI search will increasingly prioritize engineering integration capabilities, not just model reasoning alone. Zhipu AI's new feature, now officially launched, demonstrates the immense potential and practical application value of AI in the search field.
The Underlying Logic of Excellent Products
In a highly competitive market, many companies claim to have outstanding products, but these products often struggle to gain market recognition and customer favor. This article examines the underlying logic of truly excellent products by analyzing the perspectives of businesses, the market, and customers, introducing the concept of 'Triple-Excellent Products'. The article first defines what constitutes a truly excellent product, explaining the criteria for excellent products as recognized by businesses, the market, and customers. Excellent products recognized by businesses include the dimensions of product value, customer value, and business value; excellent products recognized by the market focus on customer concentration, user journey, and competitors; excellent products recognized by customers emphasize value experience, herd mentality, and personal preference. The article further analyzes how to enhance performance through the intersection of these three dimensions and presents a logical diagram of product value, emphasizing the importance of functional value, sensory value, and emotional value. Finally, the article concludes that the key to creating excellent products lies in the comprehensive consideration of product value, customer value, and business value, and proposes the view that in a competitive market, products either stand out or fall behind.
Market Landscape of AI Companions
This article delves into the current market status and development trends of AI companions, particularly focusing on their rapid growth and commercial potential in the intelligent era. The article begins by introducing the background of AI companions, noting that since the release of ChatGPT, these products have entered a period of rapid development, meeting the growing emotional needs of people. Next, the article lists major AI companions on the market, such as Character AI, Talkie (Hoshino), and Xiaoice, and analyzes their market performance and commercial success. The article provides detailed data showing a surge in downloads and revenue for AI+Chatbot applications in 2023 and 2024, with top applications like Character AI and Talkie AI standing out. Additionally, the article forecasts the future growth trends of the global emotional AI market, expecting significant growth by 2030. The business model section discusses various profit methods of AI companions, including advertising revenue, paid subscription, data-driven advertising, and value-added services. Finally, the article categorizes different types of AI companions and their core functions, and analyzes the characteristics and advantages of products like Character AI, Talkie AI, and Replika in detail.
Exploring the Virtual Digital Human Industry: Current Status, Challenges, and Future
This article delves into the current state, development trends, commercialization models, and applications of the virtual digital human industry across various fields, while also analyzing the legal and compliance risks it faces. The article cites data highlighting the robust growth of the virtual human industry, attributing this growth to factors such as the pull of the digital industry, policy encouragement, and e-commerce demand. It introduces the two primary commercialization models for virtual humans: custom development and SaaS platform services, illustrating their wide-ranging applications in e-commerce, education, and other sectors. Furthermore, the article explores the legal risks associated with the virtual human industry, such as the misuse of portraits and compliance concerns, and proposes countermeasures, including strengthening legal and regulatory frameworks, establishing industry standards, enhancing technical oversight, and raising public awareness. Finally, the article looks toward the future of the virtual digital human industry, emphasizing its immense potential and value to society, provided it adheres to legal and ethical principles.
Must-Read for AI Enthusiasts! Anthropic CEO's Long Essay - Predicting a Positive Future for Superintelligence
Anthropic CEO Dario Amodei delves deeply into the potential positive impacts of Superintelligence on human society. The article first predicts that Superintelligence could emerge as early as 2026, characterized by intelligence surpassing top experts, multi-interface working environments, and the ability to execute long-term tasks. It then discusses the application prospects of AI in fields such as biology, neuroscience, and economic development, emphasizing that AI is not just a data analysis tool but a virtual biologist that can accelerate the entire research process. The article also predicts that AI will accelerate advancements in biomedicine, potentially achieving all biological and medical progress that humans might achieve over the next 50-100 years within a few years, including prevention and treatment of infectious diseases, cancer, genetic disorders, and possibly even doubling human lifespan. Additionally, AI's application in neuroscience is expected to significantly improve the treatment of mental illnesses, potentially curing them and enhancing human cognitive and emotional abilities. The article concludes by discussing the challenges AI faces in addressing global poverty and inequality, emphasizing the need for global collaboration.
AMD Unveils Powerful AI Chip, Rivaling NVIDIA's Blackwell, Set for 2025 Launch

At the Advancing AI 2024 event in San Francisco, AMD unveiled a series of new AI chips, including the Ryzen AI Pro 300 series processors, Instinct MI325X accelerator, and EPYC 9005 Turin processor. These products are designed to enhance AI computing performance, particularly in large model training and inference, challenging NVIDIA's Blackwell series. The Ryzen AI Pro 300 series processors are tailored for AI PCs, utilizing a 4nm process and combining GPU and NPU to deliver up to 55 TOPS of AI computing power. The Instinct MI325X accelerator, based on the AMD CDNA 3 architecture, offers industry-leading memory capacity and bandwidth, with production slated for the fourth quarter of 2024. The EPYC 9005 Turin processor, built on the Zen 5 architecture, is suitable for enterprise, AI, and cloud service applications, showcasing significant performance improvements. AMD also introduced new AI network interconnect technologies and software support to strengthen its position in the AI landscape. AMD's investment in the software ecosystem, particularly its support for the ROCm open software stack, further solidifies its strategic approach in the AI field.
$650 Million! AI Agents' Largest Acquisition: Jake Keller Interview on Vertical AI Agents as the New Opportunity to Become a $10 Billion Unicorn, Decided in Just 48 Hours
Jake Keller detailed in an interview how his company CoCounsel rapidly shifted to new product development based on GPT-4 technology and was acquired by Thomson Reuters for $650 million in a short period. He emphasized the unique value of Vertical AI Agents, opposing the notion of 'GPT wrapper' (meaning a basic shell around GPT), and argued that in vertical domains, the ability to decompose problems and write specific prompts is a non-replicable intellectual asset. Jake also shared his entrepreneurial journey in the Legal Technology field, from early failures relying on user-generated content to pivoting to Natural Language Processing (NLP) and Machine Learning, ultimately experiencing a major turning point after the release of ChatGPT. He highlighted the importance of full commitment and rapid iteration, as well as the critical role of Test-Driven Development (TDD) in improving AI accuracy. Additionally, he discussed the performance of OpenAI's o1 model in handling complex tasks, particularly its precision and meticulousness in legal brief analysis. Jake Keller's personal leadership and team collaboration were also key factors in the success.
Tesla's Robotaxi Unveiled: Musk's Vision for the Future of Transportation (Full Text)
At the 'Robotaxi Day' event on October 11, 2024, Tesla unveiled its core products and technologies for the future of transportation. Musk arrived in the world's first steering-wheel-free, pedal-free Cybercab, emphasizing Tesla's vision for the future of transportation. The event showcased three main products: Robotaxi, Robovan, and Tesla Bot, and detailed advancements in Full Self-Driving (FSD) technology, claiming its safety level could surpass human driving by ten times. Tesla plans to launch fully unsupervised FSD in Texas and California, further enhancing the autonomous driving capabilities of Model 3 and Model Y. Through autonomous driving technology, Tesla aims to increase vehicle utilization by 5 to 10 times, opening up new business models.
Geoffrey Hinton and John Hopfield Win 2024 Nobel Prize in Physics

The Royal Swedish Academy of Sciences announced on October 8th that the 2024 Nobel Prize in Physics was awarded to John J. Hopfield and Geoffrey E. Hinton for their pioneering work in using artificial neural networks to achieve machine learning. Their contributions have laid the foundation for modern machine learning, driving significant advancements in science, engineering, and everyday life. Geoffrey Hinton is a pioneer in deep learning, known for his contributions to the backpropagation algorithm, Boltzmann machines, and convolutional neural networks. Notably, the convolutional neural network 'Alexnet', developed by Hinton and his students Alex Krizhevsky and Ilya Sutskever, achieved a breakthrough in the ImageNet 2012 Challenge, significantly advancing the field of computer vision. Hinton also proposed capsule networks as an alternative to convolutional neural networks, demonstrating stronger adaptability to noisy data. John Hopfield is renowned for his classic model in neural networks, the Hopfield network. His work introduced the concept of precise binary neurons and energy functions, providing effective solutions for auto-associative storage and optimization problems. Hopfield networks have been widely applied in solving combinatorial optimization problems and image recognition tasks, contributing to the development of computational neuroscience. The research of these two scientists has not only had a profound impact in academia but has also brought revolutionary changes to practical applications, such as significant progress in speech recognition and object classification. Their work demonstrates the powerful application of physical tools in machine learning, providing new ways to address societal challenges. In the future, their research may have a profound impact on AI ethics and security.
Nobel Prize in Chemistry Awarded to DeepMind: How AI Revolutionized Protein Research?
The 2024 Nobel Prize in Chemistry was awarded to scientists who made groundbreaking contributions in protein structure prediction and design. DeepMind's AlphaFold2, utilizing artificial intelligence, successfully predicted the structures of nearly all known proteins, marking a pivotal moment in protein science. The article delves into the history of protein research, tracing its evolution from early experimental methods to the emergence of computational biology and the subsequent application of deep learning to protein folding problems. AlphaFold2's exceptional performance in the CASP competition, achieving accuracy rates exceeding 90% and outperforming competitors, has not only transformed how biologists study proteins but also inspired the development of new algorithms and biotechnology companies. While AlphaFold2 has made remarkable progress in protein science, challenges remain, such as simulating protein changes over time and their behavior within cellular environments. The article highlights the complexity and significance of protein folding, illustrating how scientists have gradually unraveled the mysteries of protein structure through experimental and computational approaches.
The AI Image Revolution: Just Getting Started
This article dives into the latest advancements in AI image processing, particularly the use of Transformer architecture in image generation, exemplified by models like Stable Diffusion 3.0 and Flux.1. It also explores the control capabilities of ControlNet in image generation. The article highlights how Transformer architecture, with its powerful sequence modeling capabilities, has significantly improved the quality and controllability of image generation. Stable Diffusion 3.0 and Flux.1 models, by incorporating the Multimodal Diffusion Transformer Architecture (MMDiT), have achieved high-resolution image generation and intricate detail processing. ControlNet enhances the precise control of image generation by adding extra conditional inputs, particularly for lighting, contours, and composition. The article also emphasizes the importance of 1K resolution in AI image generation and understanding, as it allows for capturing more information and details, enhancing image processing capabilities. Generative AI faces commercialization challenges, with many prominent applications seeking commercialization through acquisition or integration into specific industries. AI has also made significant strides in medical image analysis, with notable examples like Google's Med-Gemini series models and MIT's Mirai system. The development of multimodal AI technology, such as GPT-4o and Meta's Chameleon model, has enabled early fusion of text and images. Looking ahead, with advancements in Transformer architecture and cross-modal information processing capabilities, AI image generation and understanding are poised for a new wave of breakthroughs. OpenAI's o1 inference model, designed to handle complex reasoning tasks, could potentially address the 'logic' problem in generation, making image generation more aligned with physical laws. AI technology is not only rewriting applications but also reconstructing itself through the latest architectures and algorithms, driving rapid progress in the field.
Sequoia Capital Interviews NVIDIA's Jim Fan: Building AI Brains for Humanoid Robots, and Beyond
Sequoia Capital and NVIDIA's Jim Fan had an in-depth conversation about the future development of humanoid robots and embodied AI. Jim Fan emphasized the technological leap in low-level motion control for humanoid robots, similar to the breakthrough of GPT-3 in natural language processing. He pointed out that successful robotics requires a combination of internet-scale data, simulated data generated, and data collected by real robots to drive the development of robotic foundational models. Additionally, Jim Fan discussed the potential of general models in the robotics field, similar to the successful experience in the NLP field, where prompt tuning can solve various expert tasks. He also mentioned the significant impact of hardware cost reduction and the development of foundational models on the revival of robotics technology. In the virtual world, Jim Fan shared attempts to build embodied AI agents, such as the MineDojo and Voyager projects, emphasizing the autonomous learning and exploration capabilities of AI agents in games, and looking forward to the versatility of AI agents in both virtual and physical worlds. He also discussed the continuity between the virtual world and the physical world, emphasizing the application of domain randomization techniques in robot training, as well as the potential and limitations of the Transformer architecture in robotic foundational models.
Express Delivery - 39 US AI Startups Raised Over $100 Million in 2024: Complete List
This article presents a comprehensive list of 39 US AI startups that successfully raised over $100 million in funding during 2024. These companies span diverse sectors, including legal tech, software development platforms, and AI chip development. They have attracted investment from prominent venture capital firms like Bain Capital, Sequoia Capital, and SoftBank through multiple funding rounds. Despite claims of AI fatigue, venture capitalists remain enthusiastic about the AI sector, with AI companies accounting for 28% of all venture capital raised in the third quarter. Notably, OpenAI's massive $6.6 billion funding round in the third quarter stands as the largest venture capital deal ever, highlighting the market's high expectations for leading AI companies and setting a precedent for the entire industry. These AI startups are leveraging their funding to accelerate innovation and application development across various fields.
Tencent Research Institute Dialogue with Former OpenAI Researcher: Why Greatness Cannot Be Planned? | Leave a Comment to Win Books
Tencent Research Institute hosted a dialogue with former OpenAI researchers Kenneth Stanley and Joel Lehman, delving into the relationship between innovation and goal setting. The article emphasizes the importance of novelty and openness in driving technological progress, pointing out that goal thinking can sometimes hinder innovation, while interest and novelty are better criteria. The discussion covers how to balance goal orientation and free exploration in organizational management, avoiding bureaucracy and excessive goal orientation. The article also explores OpenAI's success experience, highlighting the courage of the leadership, cultural factors, talent, and intuition in innovation, and pointing out that OpenAI's success has historical contingency, difficult to predict and plan.
The Dawn of Generative AI [Translation]
![The Dawn of Generative AI [Translation]](https://www.sequoiacap.com/wp-content/uploads/sites/6/2024/10/Hero-o1.jpg)
This article delves into the development trends of Generative AI, particularly the shift from 'Fast Thinking' to 'Slow Thinking', which is the evolution from pre-trained quick responses to deep reasoning. The article introduces OpenAI's Strawberry model, which demonstrates strong capabilities in strongly logical domains through computational reasoning. Generative AI is significant in model competition, the current state of the application layer, and the transformation of AI as a service, changing traditional cloud computing and SaaS business models and driving the emergence of new intelligent applications. AI companies are selling work outcomes rather than software usage rights, adopting high-touch, high-trust delivery models, and opening up new realms of automated work. The article looks forward to the future of Generative AI, particularly the proliferation of multi-agent systems and AI's application in complex tasks, signaling the start of Artificial General Intelligence (AGI).
YC Demo Day Project Overview: Four New Trends in AI Startups, 22 AI Startups to Watch
YC Demo Day is one of the most anticipated startup pitch events of the year, and this summer's Demo Day showcased four new trends in AI startups: AI Robotics, AI-powered Web Browsing and Software Operation, AI Applications in Specialized Fields, and AI Development Tools. The article detailed these trends and listed 22 AI startups to watch. AI Robotics, benefiting from the development of multimodal AI and visual language models, is poised for a revolutionary advancement. These models enable robots to learn by observing and mimicking human behavior. AI-powered Web Browsing and Software Operation empowers startups to interact with the web and software like humans, suggesting that AI may one day independently complete complex tasks without human supervision. AI Applications in Specialized Fields demonstrate how AI technology is infiltrating professions such as construction, healthcare, and law enforcement, enhancing efficiency and potentially revolutionizing certain industries. The surge in AI Development Tools provides developers with more effective ways to leverage foundational AI models, accelerating the AI development process and enhancing the capabilities of AI agents and software. The article also listed 22 AI startups to watch, covering fields from robotics to healthcare, construction, transportation, and more, showcasing the broad application and immense potential of AI technology.
A Short Summary of Chinese AI Global Expansion

The article explores the trend of Chinese AI companies expanding globally, paralleling Zheng He's historic voyages. By 2024, Chinese firms have notably increased their international presence, with 751 out of 1,500 global AI companies based in China and 103 expanding overseas. Key players like Huawei, Tencent, and Alibaba focus on Southeast Asia and the Middle East, aligning with strategic initiatives like the Belt and Road. The expansion is driven by domestic market saturation and regulatory pressures. The article emphasizes localization, open-source contributions, and ESG strategies as critical success factors, while noting the challenges in adapting to foreign markets.