BestBlogs.dev Highlights Issue #25
Subscribe Now👋 Dear friends, welcome to this week's curated article selection from BestBlogs.dev!
🚀 This week has witnessed several major breakthroughs and innovations in the AI field. Anthropic has introduced the MCP (Model Context Protocol), establishing a unified client-server architecture to bridge LLM applications with data sources. Alibaba Cloud's Qwen2.5-Turbo has achieved remarkable progress in long-context processing, capable of summarizing 690K tokens in 45 seconds with a 4.3x inference speed improvement. DeepSeek's newly released R1-Lite-Preview model has demonstrated superior performance over OpenAI's o1 in both the American Mathematics Competition and global programming contests. In product innovation, Mistral AI has unveiled Pixtral Large, a 124B-parameter multimodal model supporting up to 30 high-resolution images, alongside their feature-rich free chat assistant Le Chat. In development tools, Cursor has upgraded to version 0.43, introducing Composer Agent to enhance project comprehension and code review capabilities. Additionally, NVIDIA CEO Jensen Huang has predicted a million-fold reduction in computing costs over the next decade, while Professor Zheng Yongnian has offered profound insights into AI's societal impact, illuminating both the technological trajectory and broader implications of AI. Let's explore this exciting new era of AI together!
💫 Weekly Highlights
- Anthropic launches MCP protocol, establishing unified standards and security measures for LLM application data integration
- Alibaba Cloud's Qwen2.5-Turbo achieves 1M token context support with 4.3x inference acceleration
- DeepSeek R1-Lite-Preview outperforms o1 in mathematical and programming competitions, with plans for full open-source release
- Mistral AI debuts Pixtral Large multimodal model, featuring 128K context window and advanced multi-image processing
- Cursor 0.43 introduces Composer Agent, revolutionizing code review and project management capabilities
- Tencent Cloud AI Code Assistant showcases innovative dual-cycle development methodology
- Microsoft unveils LazyGraphRAG, achieving 99.9% cost reduction in data indexing compared to traditional methods
- NVIDIA CEO Jensen Huang outlines vision for AI manufacturing revolution and computing cost reduction
- Meta drives industry innovation through Llama 2 open-source initiative, marking strategic transformation
- Anthropic CEO shares insights on large model development, emphasizing synthetic data and training optimization
Interested in diving deeper into these fascinating AI developments? Click through to explore the original articles and discover more exciting innovations!
Table of Contents
- In-depth Analysis: Anthropic MCP Protocol
- Qwen-2.5-Turbo: Million-Token Context, 4.3x Faster Inference, and the Future of RAG
- DeepSeek's Inference Model Competes with o1, Set to Open-Source
- Mistral's Major Move: 124B Parameter Multimodal Model, Canvas, Search, Image Generation Free to Use
- Tencent Hunyuan Large Model Core Research Papers Revealed: Scaling Law, MoE, Synthetic Data, and More
- OpenAI Realtime API: The Missing Manual
- Optimizing foundation models from Medprompt o1
- LazyGraphRAG sets a new standard for GraphRAG quality and cost
- Understanding the Full Picture of Recommendation Systems from Scratch
- Does GitHub Copilot improve code quality? Here’s what the data says
- No Silver Bullet for RAG! Four-level difficulty, latest survey covers datasets, solutions, and teaches the correct usage of 'LLM + External Data'
- Comprehensive Guide! Hands-On Instructions on How to Train Large Language Models in Large-Scale Clusters
- Updated! Cursor with Agent is groundbreaking.
- Tencent Cloud AI Code Assistant: Reflections and Methodologies on Product Development
- How to improve search without looking at queries or results
- Perplexity's Growth Strategy: Insights from the Growth Lead
- 8000-word Competitive Analysis: In-depth Analysis and Reflections on AI Dialogue Products
- Leading Growth Experts in Silicon Valley Share: The Seven Core Levers for Growth in Consumer-facing SaaS Products
- Menlo VC Report: The 4 Most Valuable AI Use Cases, AI Expenditure This Year is 6 Times Last Year's
- Runway and Luma are at it again! Hands-on testing of new features, who will come out on top?
- OpenAI's Promoted AI PDF Tool, a Product with 500,000 Users in One Year, Team of Only 5 People | Z Talk
- Jensen Huang's Latest 10,000-Word Dialogue: NVIDIA Reduced Computational Marginal Cost by 1,000,000 Times in a Decade
- Meta's Renaissance: Embracing Open Source AI Models
- CEO of Anthropic: Scaling Law Has Not Hit a Wall
- Interview with Khan Academy Founder: What is the Biggest Difference Between China and the U.S. in AI in Education? | Jiazi Light Years (a media brand)
- Professor Zheng Yongnian: The Ultimate Thinking on AI and Humanity — How to Avoid Becoming Sheep That Can Speak? | AI and Society 100 Questions
- My Experience in Post Training at Character.ai | 42 Chapter Press
- LWiAI Podcast #190 - AI scaling struggles, OpenAI Agents, Super Weights
In-depth Analysis: Anthropic MCP Protocol
This article provides a detailed introduction to the MCP (Model Context Protocol) protocol launched by Anthropic, which aims to address the challenge of connecting Large Language Model (LLM) applications with data sources. Through a unified client-server architecture, MCP supports local and remote resource access, driving standardization development in AI integration. The article first outlines the core concepts and architecture of the MCP protocol, including protocol layers, transport layers, message types, and connection lifecycle. Subsequently, it details how to configure and use the MCP protocol on macOS and Windows systems, including installing necessary software, creating a test database, configuring the Claude Desktop Application, and more. Additionally, the article delves into resource management, security measures, and the use of Prompts in the MCP protocol. Finally, through a workflow example named 'debug-error', it demonstrates how to handle and analyze error information encountered by users.
Qwen-2.5-Turbo: Million-Token Context, 4.3x Faster Inference, and the Future of RAG
Qwen-2.5-Turbo, the latest addition to the Qwen-2.5 series, represents a major leap forward for Chinese-developed large language models in handling ultra-long contexts and accelerating inference. It supports a context length of 1 million tokens—equivalent to 10 novels or 150 hours of audio—and can summarize 690,000 tokens in just 45 seconds, achieving 100% accuracy in detailed information retrieval tests. Leveraging a sparse attention mechanism, Qwen-2.5-Turbo's first-token return time drops from 4.9 minutes to 68 seconds when processing a million-token context, a 4.3x speed improvement. Cost-effective at 0.3 yuan per million tokens, it outperforms GPT-4o-mini in processing power. Qwen-2.5-Turbo excels in practical applications like codebase analysis, paper summarization, and classification, surpassing GPT-4o-mini and GPT-4 in various benchmark tests (RULER, LV-Eval, Longbench-Chat), especially in long-form tasks. While the model weights aren't yet open-source, demos are available on Hugging Face and ModelScope, with API access via Alibaba Cloud's large model service platform.
DeepSeek's Inference Model Competes with o1, Set to Open-Source

DeepSeek recently released its new inference model, DeepSeek-R1-Lite-Preview, which has performed exceptionally well in multiple authoritative evaluations, particularly in the American Mathematics Competitions (AMC) and codeforces, surpassing several top models including OpenAI's o1. The success of DeepSeek-R1-Lite-Preview lies in its deep thinking capabilities, achieved through reinforcement learning and long chain-of-reasoning technology. This allows the model to demonstrate detailed reasoning chains, similar to the deep thinking process of the human brain. Additionally, the model has shown advantages in handling complex problems, such as solving logical traps in cognitive ability tests and tackling university physics problems. Although the model currently only supports web usage and is not fully open-sourced, DeepSeek has promised to fully open-source the official version of the DeepSeek-R1 model in the future, along with releasing technical reports and deploying API services. This news has sparked widespread attention and anticipation within the domestic AI community.
Mistral's Major Move: 124B Parameter Multimodal Model, Canvas, Search, Image Generation Free to Use
Mistral AI has recently announced two major updates: the 124B parameter multimodal model Pixtral Large and a new chat assistant Le Chat. Pixtral Large has achieved state-of-the-art (SOTA) levels in multimodal tasks such as MathVista, DocVQA, and VQAv2, with a 128K context window length, capable of processing up to 30 high-resolution images or approximately 300 pages of books. The model is available for research and educational use under the Mistral research license and can be downloaded for free on the Hugging Face platform. Le Chat is a free chat assistant that integrates web search, image generation, document understanding, and more. Users can perform web searches, use Canvas for creative brainstorming, upload PDFs for analysis and summary, and even generate images. The launch of Le Chat signifies a significant advancement in multimodal AI applications and user experience, particularly due to its free availability, making advanced AI technology more accessible.
Tencent Hunyuan Large Model Core Research Papers Revealed: Scaling Law, MoE, Synthetic Data, and More

With the widespread application of ChatGPT, the capabilities of large language models have been validated in multiple fields and have profoundly influenced the research work of the Tencent Hunyuan team. The Tencent Hunyuan team has long been dedicated to large model research. Through innovative research and technical accumulation, they have enhanced the foundational capabilities of large models and deeply integrated these capabilities with business to promote the application of generative AI. The Tencent Hunyuan team has released the industry's largest parameter scale MoE open-source model, Tencent Hunyuan Large, which demonstrates superior performance under high-quality synthetic data and advanced model architectures, outperforming similar models in extensive benchmark tests. Additionally, the team has made significant progress in several cutting-edge research areas, including exploring the scaling law between batch size and optimal learning rate for large models, proposing the heterogeneous mixture of experts (HMoE) model, constructing the fine-grained and diverse instruction-following evaluation dataset DINGO, and conducting innovative research studies on dataset construction, detection, and mitigation of large model hallucination problems. These research achievements not only provide theoretical foundations and empirical conclusions for the training of large models by the Tencent Hunyuan team but also offer valuable insights and guidance to the entire large model community.
OpenAI Realtime API: The Missing Manual
The article opens with a discussion of the author's experience at OpenAI DevDay Singapore, where they utilized OpenAI's real-time API to create an encoding voice AI agent. The author imparts insights gained from working with the raw real-time API, particularly in the lead-up to their presentation at the event. Subsequently, the article shifts to the insights of Kwindla Kramer, who delineates the evolution from GPT-4 to GPT-4o and the most recent updates to OpenAI's real-time API. Kramer elucidates the API's architecture, its approach to event and audio processing, as well as latency optimization strategies, supplementing these with code examples and usage advice pertaining to the Pipecat framework. Furthermore, the article addresses critical technical challenges, including Voice Activity Detection (VAD), phrase endpoint detection, and context management, accompanied by practical development guidance and illustrative code samples.
Optimizing foundation models from Medprompt o1
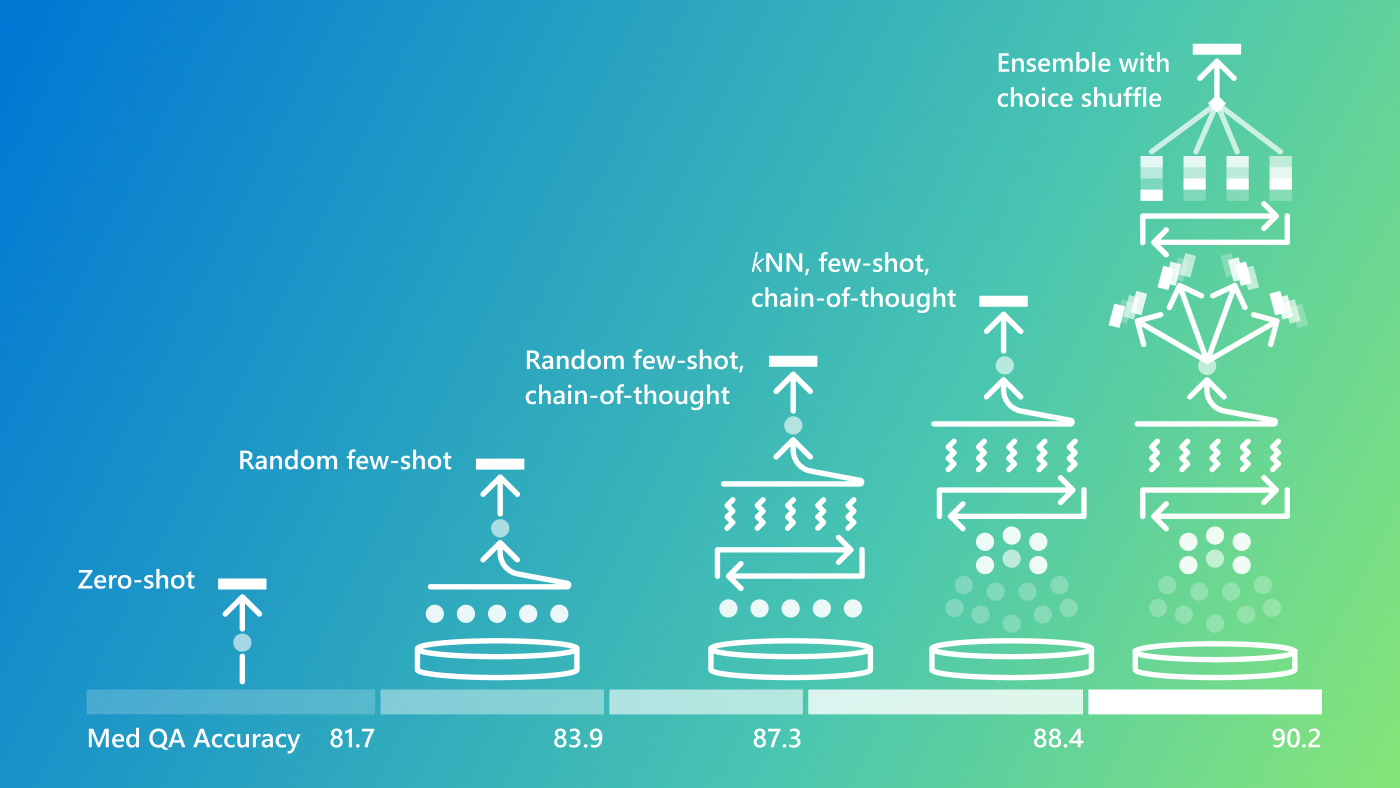
The article from the Microsoft Research Blog explores the progression from the Medprompt approach to the OpenAI o1-preview model, focusing on the optimization of foundation models for specialized tasks, particularly in the medical domain. Medprompt, developed by Microsoft, leverages multiphase prompting to enhance the performance of GPT-4 without fine-tuning, achieving high accuracy on the MedQA benchmark. However, the OpenAI o1-preview model, which integrates run-time strategies directly into its reinforcement learning-based design, demonstrates superior performance, reaching 96% accuracy on the same benchmark without sophisticated prompt guidance. The article delves into the differences between GPT models and the o1 series, emphasizing the built-in run-time reasoning capabilities of the latter, which significantly outperform GPT-4 with Medprompt, albeit at a higher per-token cost. It also discusses various prompting strategies, such as Tailored Prompt, Ensembling, and Few-Shot Prompting, and their effectiveness with the o1-preview model. Additionally, the article examines the performance of these models on multilingual benchmarks, including the Japanese Medical Licensing Examination (JMLE), and explores the impact of reasoning tokens on model accuracy. The article concludes by highlighting the importance of run-time strategies, benchmark saturation, and the transition from benchmarks to clinical applications, emphasizing the need for more challenging benchmarks and rigorous clinical trials to evaluate AI models effectively in real-world healthcare settings.
LazyGraphRAG sets a new standard for GraphRAG quality and cost

The article introduces LazyGraphRAG, a groundbreaking approach to graph-enabled Retrieval-Augmented Generation (RAG) that aims to address the limitations of traditional vector RAG and full GraphRAG methods. Unlike conventional methods that require upfront summarization and indexing of source data, LazyGraphRAG defers all Large Language Model (LLM) usage until query time, thereby significantly reducing initial costs and improving scalability. The approach combines best-first and breadth-first search dynamics in an iterative deepening manner, allowing for efficient query processing and answer generation. Key performance metrics highlight LazyGraphRAG's superiority across various cost-quality trade-offs. For instance, LazyGraphRAG's data indexing costs are identical to vector RAG and just 0.1% of full GraphRAG's costs. Additionally, LazyGraphRAG outperforms all competing methods on local queries at comparable query costs to vector RAG, and it shows comparable answer quality to GraphRAG Global Search for global queries at more than 700 times lower query cost. The article also presents experimental results demonstrating LazyGraphRAG's state-of-the-art performance across a range of metrics, including comprehensiveness, diversity, and empowerment. LazyGraphRAG is set to be released as part of Microsoft's open-source GraphRAG library, offering a unified query interface for both local and global queries over a lightweight data index. This development promises to democratize access to high-quality, cost-effective AI-driven data retrieval solutions.
Understanding the Full Picture of Recommendation Systems from Scratch
This article details how to build a recommendation system from scratch, covering recommendation algorithms, system architecture, user profiles, and content profiles. The article first emphasizes the critical role of data, algorithms, and architecture in recommendation systems and introduces the main steps of a recommendation system, including candidate retrieval, filtering, ranking refinement, mixing, and strong rules. Subsequently, it explores specific methods and application scenarios of candidate retrieval strategies, coarse-tuning strategies, and ranking refinement strategies, and details the basic principles, construction processes, and advantages and disadvantages of logistic regression and deep learning models. Additionally, the article discusses the application of feature embedding techniques in recommendation systems and the solutions to the exploration-exploitation (EE) problem, diversity problem, and contextual problem. Finally, the article introduces various key technologies and applications of recommendation systems, including cold start, causal recommendation, sequential recommendation, graph neural networks, knowledge graphs, reinforcement learning, multi-modal content recommendation, and dialogue systems, and discusses the evaluation criteria for algorithms. The article also explores the experimental methods of recommendation systems and their impact on information inequality and echo chambers, as well as the application and potential impact of recommendation algorithms on platforms like video channels.
Does GitHub Copilot improve code quality? Here’s what the data says

The article presents a comprehensive study on the impact of GitHub Copilot on code quality, conducted by GitHub's research team. The study employed a randomized controlled trial involving 202 experienced developers, half of whom were given access to GitHub Copilot while the other half were not. Participants were tasked with writing API endpoints for a web server, and their code was evaluated through unit tests and expert reviews. The findings indicate that code authored with GitHub Copilot exhibited significant improvements in functionality, readability, reliability, maintainability, and approval rates. Specifically, developers using GitHub Copilot were 56% more likely to pass all unit tests, wrote 13.6% more lines of code without readability errors, and saw improvements in readability, reliability, maintainability, and conciseness by 1-4%. Additionally, code written with GitHub Copilot was 5% more likely to be approved for merging. The study concludes that GitHub Copilot aids in writing high-quality code by enabling developers to focus more on refining code quality rather than just making it functional. This aligns with previous research showing increased developer confidence and productivity when using GitHub Copilot.
No Silver Bullet for RAG! Four-level difficulty, latest survey covers datasets, solutions, and teaches the correct usage of 'LLM + External Data'
This article, reported by Xin Zhi Yuan, mainly discusses the application and challenges of Retrieval-Augmented Generation (RAG) technology in handling user queries of varying difficulty levels. The article first points out that due to the limitations of large language models in terms of parameter size and knowledge updates, many real-world tasks require connecting to external data sources, which has led to the growing interest in RAG technology. However, simply connecting to external data is not sufficient; many user queries are very complex and require optimization from various aspects, such as retrieving relevant data, accurately interpreting user intent, and fully utilizing the reasoning capabilities of large models. The article proposes a RAG task classification method, dividing user queries into four levels: explicit fact queries, implicit fact queries, explainable reason queries, and implicit reason queries. Each level has its unique challenges and solutions, requiring different techniques and methods to optimize performance. Additionally, the article discusses three main ways to integrate external data into large language models (LLMs): context, small models, and fine-tuning, and analyzes their respective advantages, limitations, and the types of problems they are suitable for solving. The article emphasizes that there is no one-size-fits-all solution for RAG; the best performance depends on choosing the right techniques and methods for each task.
Comprehensive Guide! Hands-On Instructions on How to Train Large Language Models in Large-Scale Clusters
The Kuaishou AIP Team has published and open-sourced a training solution for Large Language Models (LLM) in large-scale clusters at USENIX ATC '24. The solution addresses storage and computational efficiency issues in large model training through hybrid parallelism, communication optimization, and GPU memory management. Specifically, it includes: dispersing model states and intermediate activations through hybrid parallelism to reduce communication volume; optimizing communication overhead using DP overlap and TP overlap schemes; achieving computation and communication overlap through all-gather overlap GEMM and reduce scatter operations; introducing context parallelism (CP) to address the non-scalability and high communication volume of TP; enhancing training efficiency and VRAM utilization through GEMM last recomputing and pipeline aware offloading strategies. Additionally, the team proposed activation reconstruction strategies and parallel configuration optimization, significantly improving model FLOPs utilization (MFU). Future research directions include trillion parameter scale Mixture of Experts (MoE) models, expanding sequence length, RLHF framework, low-precision training, and the introduction of heterogeneous computing.
Updated! Cursor with Agent is groundbreaking.

This article details the updates in the latest version 0.43 of the AI-assisted coding tool Cursor, particularly the introduction of its core feature, the Composer Agent. The Composer Agent has complete project understanding and editing capabilities, helping developers more efficiently conduct code reviews and project management. The article showcases the powerful functionality of the Composer Agent in handling complex projects through actual user tests, such as parsing entire files, reviewing code, and suggesting improvements. Furthermore, the article mentions the Bug Finder feature, which, although currently in Beta and with certain risks, aims to help developers discover code issues early. In addition to the updates on Cursor, the article also references research data from GitHub Copilot, demonstrating the significant impact of AI tools on improving developers' coding speed and code quality. Overall, the article emphasizes the importance and potential of AI-assisted coding tools in modern software development, foreshadowing a significant transformation in developers' working methods.
Tencent Cloud AI Code Assistant: Reflections and Methodologies on Product Development
This article systematically elaborates on the product layout, overall architecture, R&D system, and technical methods of Tencent Cloud AI Code Assistant. It first reviews the development history of AI Code Assistant, from the first-generation code completion function to the third-generation multi-dimensional code completion based on large language models, demonstrating technological advancements and expanded application scenarios. Subsequently, it introduces the overall architecture of Tencent Cloud AI Code Assistant, including the main screen coding mode in IDE and the side screen Chat mode, as well as the code review scenario in the internal source code hosting platform. In the section on the product R&D system and technical methods, the article describes Tencent's dual-loop driven R&D system, emphasizing the iterative process from user needs, through data engineering, model training, evaluation, and deployment, along with simultaneous product feature iterations. The article also delves into the pre-training and fine-tuning strategies of code large models, including methods for developing high-quality code data, FIM technology, code data ratio, SFT data development process, etc. Additionally, it introduces core strategies and algorithms such as Trigger, Prompt, Stop, and Show to ensure the accuracy of code completion and user experience. The conclusion emphasizes Tencent's systematic thinking and technical methods in the AI-driven code intelligence track, looking forward to efficient product iterations and ultimate user experience in the era of intelligence.
How to improve search without looking at queries or results
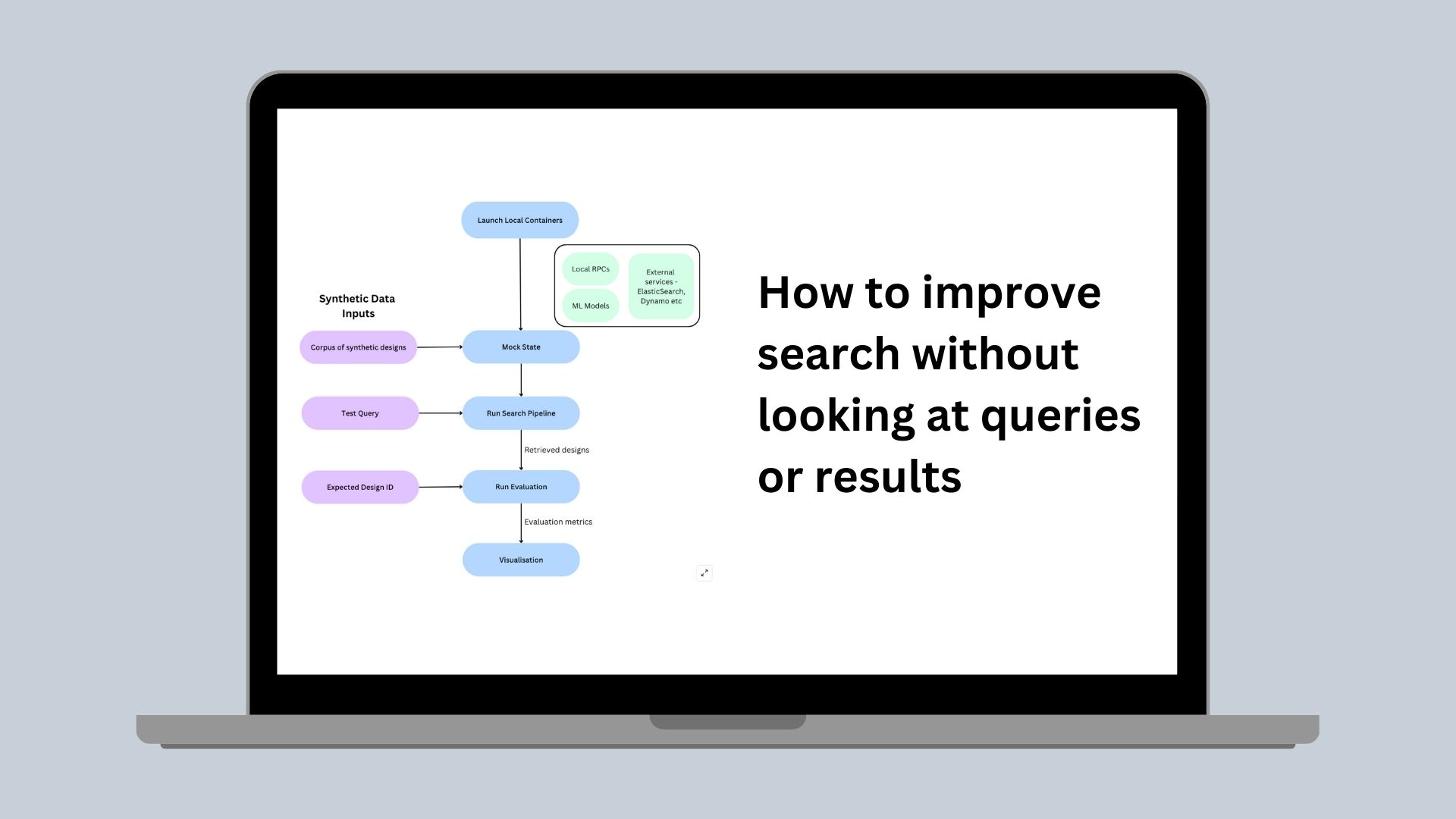
Canva, with 200 million monthly active users and over 30 billion designs, faces significant challenges in ensuring effective search functionality. Traditional evaluation methods, using sampled user queries and expert human judges, are not feasible due to privacy concerns. Canva's core value of 'Be a Good Human' necessitates strict privacy measures, making real user data usage impossible. To address this, Canva developed a novel approach using generative AI to create realistic but synthetic content and queries. This method allows for the creation of a labeled evaluation dataset without compromising user privacy. The article details the process of generating these datasets, the tools used for evaluation, and the challenges encountered. The original state of Canva's search evaluation involved limited offline testing followed by online experimentation, which had several drawbacks. The ideal state aimed for a custom dataset and evaluation pipeline that allowed for reproducible, fast, and realistic results, enabling parallel experimentation without blocking other engineers. The synthetic dataset creation process involves seeding GPT-4 with design topics and types, generating realistic titles and content, and creating queries with varying difficulty levels. This dataset is then used to evaluate the search pipeline locally using Testcontainers, ensuring that the results mirror production behavior. The evaluation tool, built using Streamlit, allows engineers to visualize and compare results, facilitating rapid iteration and informed decision-making. The impact of this system includes rapid iteration, positive correlation between offline and online results, and enhanced local debugging capabilities. Canva plans to continue expanding its datasets with more realistic features and improving tooling to allow engineers to efficiently self-serve their specific synthetic data needs.
Perplexity's Growth Strategy: Insights from the Growth Lead
In an interview, Raman Malik, Perplexity's Growth Lead, discussed the company's approach to user growth, retention, brand marketing, and team building. He emphasized the crucial role of A/B testing, while acknowledging its limitations. He highlighted the importance of both significant initiatives and iterative improvements (micro-optimizations) to drive sustained growth. Malik detailed Perplexity's strategies for user growth and retention, emphasizing the power of word-of-mouth marketing and the importance of establishing appropriate metrics and partnerships to enhance retention. He also discussed optimizing user retention through targeted user segmentation, platform diversification, and refined messaging. The significance of CAC and LTV was also underscored. Regarding brand marketing, Malik shared insights from paid advertising campaigns on platforms like Lyft and TikTok, emphasizing the value of incremental reach and the power of community-driven marketing. Finally, he discussed team building and recruitment, highlighting the advantages of hiring founders and individuals with entrepreneurial experience, and the use of interviews and written assessments to evaluate candidate skills and adaptability.
8000-word Competitive Analysis: In-depth Analysis and Reflections on AI Dialogue Products
This article provides a detailed analysis of five popular AI dialogue products (iFlytek Spark, Wenxin Yiyan, Tongyi Qianwen, Kimi, Doubao) in terms of page layout, dialogue interaction, feature design, and user experience. The article begins by outlining the page layout and feature design characteristics of each product, including iFlytek Spark's vertical structure layout and Kimi's internet search function. Subsequently, the article delves into the internet search and deep search functions, analyzing the implementation methods and user experience differences of each product in these two areas. Additionally, the article analyzes the design differences in voice input, text polishing, input box design, loading status display, long text content generation, regeneration, and stop generation functions. Finally, the article summarizes the features and design highlights of each product, such as iFlytek Spark's 'Fresh Conversation' button and 'Group Chat' function, Tongyi Qianwen's efficiency toolset, etc. Through these analyses, the article provides valuable competitive analysis and design insights for developers and technical personnel.
Leading Growth Experts in Silicon Valley Share: The Seven Core Levers for Growth in Consumer-facing SaaS Products
This article, shared by leading growth expert Phil Carter from Silicon Valley, delves into the seven core levers for growth in consumer-facing SaaS products. The article first emphasizes the importance of building a growth team, suggesting tailored approaches based on the business model and acquisition channels, and prioritizing employees' curiosity and influence. It then discusses the selection of growth strategies, indicating adjustments should be made based on the company's position on the S-curve, with startups focusing on large-scale growth breakthroughs rather than detailed optimizations. Additionally, the article analyzes the challenges of rising CAC and low user retention rates in consumer products, proposing solutions through a combination of hardware and subscription business models and continuous product innovation. Pricing strategies, onboarding processes, and seasonal discounts are also highlighted, emphasizing the importance of personalization and effective guidance. Finally, the article uses the fitness app Ladder as an example, showcasing a successful case of significant growth achieved through team coaching and TikTok marketing.
Menlo VC Report: The 4 Most Valuable AI Use Cases, AI Expenditure This Year is 6 Times Last Year's
Menlo Ventures' report, based on a survey of 600 enterprise IT decision-makers, showcases the rapid growth and diversification of AI use cases. The report indicates that this year's enterprise expenditure on AI reached $13.8 billion, more than 6 times last year's, showing a trend of enterprises moving from experimentation to execution. The adoption rate of generative AI tools is expected to increase significantly, especially in programming, customer service, enterprise search, and meeting summarization. The report also highlights the rapid growth of the AI application layer, with enterprises investing $4.6 billion in generative AI applications in 2024, nearly 8 times the previous year's growth. The report lists four most valuable AI use cases: AI programming, AI customer service, enterprise search and retrieval, data extraction and transformation, and AI meeting summarization. Additionally, the report predicts the rise of AI agents and vertical applications, particularly in healthcare, law, financial services, and media and entertainment. In terms of the technology stack, the report notes that enterprises are adopting a multi-model strategy, no longer relying on a single vendor. The RAG (Retrieval-Augmented Generation) architecture has become mainstream, while agent architectures are also emerging. The report also forecasts a severe shortage of AI talent and potential disruption for existing enterprises.
Runway and Luma are at it again! Hands-on testing of new features, who will come out on top?

This article details the latest developments and competitive landscape between Runway and Luma in the AI-driven video content creation field. Runway has continuously launched video content expansion (Expand Video) features and the AI image generation model Frames within three days, demonstrating its innovative capabilities in adjusting video proportions, maintaining visual consistency, and controlling styles. Notably, the Frames model can precisely design the appearance, feel, and atmosphere of images, offering users a variety of stylistic worlds to choose from. Meanwhile, Luma has not been idle, introducing the new Dream Machine (AI Creative Tool), which not only supports video generation but also introduces image generation features with excellent visual effects. Luma's Dream Machine provides intuitive interaction design, reference redrawing functions, consistent character generation, video creation tools, and brainstorming features, greatly simplifying the user's creative process. The article also showcases the usability and creative potential of Luma's new features through practical tests, allowing users to generate high-quality videos and images through simple prompts and reference images. Overall, these new features from Runway and Luma not only enhance the technical level of AI-driven video content creation but also provide users with more creative possibilities.
OpenAI's Promoted AI PDF Tool, a Product with 500,000 Users in One Year, Team of Only 5 People | Z Talk
This article provides a detailed introduction to OpenAI's promoted AI PDF tool, developed by a team of only five people, which has garnered 500,000 users in less than a year and completed 2 million dialogues on the GPT Store. Despite facing strong competitors like ChatGPT, AI PDF has achieved rapid growth and financial balance by focusing on advanced PDF processing functions and user needs. The article emphasizes how the tool serves early adopters of technology, solves practical problems of handling large volumes of documents, and continuously adjusts the product to adapt to market and technological developments. Additionally, the article discusses the competitive advantages of startups versus large companies in AI applications, highlighting that small teams can provide more flexible and personalized AI experiences through innovation and risk-taking, seizing opportunities that large companies find difficult to achieve. Finally, the article explores how AI technology enhances personal and team productivity, as well as its applications in management and task allocation, pointing out the challenges of human guidance and management that AI still needs in practical applications.
Jensen Huang's Latest 10,000-Word Dialogue: NVIDIA Reduced Computational Marginal Cost by 1,000,000 Times in a Decade
In a dialogue with Harry Shum at the Hong Kong University of Science and Technology, Jensen Huang explored the transformative impact of artificial intelligence and its potential applications across various fields. Huang highlighted AI's ability to understand the true meaning of information, enabling precise data analysis and innovative applications. He noted that computational power growth exceeds Moore's Law predictions, with demand potentially increasing by 1,000,000 times in the next decade. Huang also discussed AI's role in scientific research, particularly in biology and medicine, proposing the concept of digital twins and suggesting that HKUST integrate technology and AI when establishing a medical school. Additionally, Huang shared his leadership experiences at NVIDIA, emphasizing continuous learning, transparency, and teamwork. He also addressed AI's impact on energy efficiency, noting that AI's goal is not just training models but applying them efficiently, with reasoning processes capable of discovering new energy storage methods.
Meta's Renaissance: Embracing Open Source AI Models
This article explores Meta's strategic AI transformation through the open-sourcing of its generative model Llama 2. Meta's decision to open-source Llama 2 is to catch up with competitors in the AI race and drive industry innovation. Despite profitability and legal risks, Zuckerberg believes open-sourcing drives innovation and establishes Meta's leadership in generative AI. The article further analyzes Meta's attempt to set new industry standards in AI through open-sourcing Llama 2, signaling a significant transformation. Zuckerberg believes open-source AI will become an industry standard like Linux, breaking proprietary OS dominance. Meta's AI exploration began in 2013, making significant progress in generative AI through open-source strategies. The article also discusses Meta's intention to break AI monopolies, accelerate innovation, and open new profitability opportunities by open-sourcing Llama 2. Despite non-open datasets, Llama 2 has become an important generative AI platform, attracting many developers to contribute and improve. Meta integrated its AI research team FAIR with the generative AI product team to accelerate AI technology application in products and develop artificial general intelligence (AGI). The article mentions Meta's open-source AI model Llama faces strict scrutiny and potential risks, but Zuckerberg believes open-source models pose less risk than closed ones and actively promotes AI talent recruitment and company transformation. Meta's AI investment requires a spirit of adventure, and Zuckerberg and Spotify co-founder Daniel Ek support open-source development as the best way to drive AI progress.
CEO of Anthropic: Scaling Law Has Not Hit a Wall
Anthropic CEO Dario Amodei delves deeply into the current state and future development of large models in an interview. He emphasizes that the Scaling Law has not yet peaked and believes synthetic data and chain-of-thought reasoning are effective solutions to data limitations. Amodei points out that although model capabilities continue to advance, the cost of the post-training phase in the future may exceed that of pre-training. He also discusses model naming, improvements in programming capabilities and their impact on programming careers, emphasizing the rapid progress of AI in the programming field and the potential of future IDEs. Additionally, Amodei highlights the potential and risks of models when performing tasks, proposing safety measures and sandbox environments needed as model capabilities increase. Finally, he discusses the balance between pre-training and post-training in model training, the effectiveness of RLHF and its impact on model intelligence, and the sensitivity of models to prompts.
Interview with Khan Academy Founder: What is the Biggest Difference Between China and the U.S. in AI in Education? | Jiazi Light Years (a media brand)
This article, through an interview with Khan Academy founder Salman Khan, delves into the application of AI in the education field and its impact on educational methods. The article first introduces the role of the AI tutor Khanmigo, emphasizing that AI not only does not hinder students' questioning abilities but also stimulates curiosity and self-exploration. It then discusses the potential of AI in promoting students' critical thinking and deep learning, especially in standardized exams and educational assessments. Salman Khan further elaborates on the auxiliary role of AI in education, pointing out that AI should cooperate with human teachers to jointly cultivate students' independent learning abilities and social skills. He also emphasizes the irreplaceable role of human teachers in emotional guidance and teacher-student interaction, and looks forward to the future development of AI educational devices. Finally, the article explores the impact of AI on the future social structure and human work methods, pointing out that the popularization of AI will reduce repetitive labor and increase human investment in creativity and social activities.
Professor Zheng Yongnian: The Ultimate Thinking on AI and Humanity — How to Avoid Becoming Sheep That Can Speak? | AI and Society 100 Questions
In his article, Professor Zheng Yongnian discusses the multifaceted impact of AI on human society, particularly in education, labor value, social significance, and human interaction. He emphasizes that the academic and educational communities must actively embrace AI, or they will be left behind by the times. AI is not merely a tool but also an entity that interacts with and influences human behavior. Education needs a revolution to adapt to the AI era while maintaining a balance with humanistic education. Professor Zheng Yongnian also points out that the development of AI may lead to the degradation of human thinking, necessitating an educational revolution. Additionally, the widespread use of AI may lead to significant job displacement, requiring a redefinition of the division of labor between humans and AI. He calls for humans to think about how to find meaning in life without labor, avoiding complete reliance on AI. Finally, Professor Zheng Yongnian emphasizes the importance of balanced development between humanistic and scientific cultures for humanity to grasp the direction of humanistic development, and encourages public participation in discussions about AI and society to shape the future together.
My Experience in Post Training at Character.ai | 42 Chapter Press
This article, shared by Ted, details his practical experience in Post Training at Character.ai. It begins by introducing the core advantages of Character.ai, including fully self-developed models, cost advantages brought by Noam Shazeer, and user preference alignment. Ted emphasizes Character.ai's focus on the AGI field, which has led to a later start in commercial exploration, but he remains optimistic about the future of AI companion products. The article then describes the workflow and methods of Post Training in detail, including the three mainstream approaches: SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback), and DPO (Direct Preference Optimization), as well as the importance of data alignment and iterative path design. Ted points out that the purpose of Post Training is to teach large models to respond correctly to human questions, and data alignment and efficient iterative path design are key to success. The article also discusses how model fine-tuning can be optimized through frequent testing and user data analysis, and how product design and model pairing can reduce voice latency. Ted emphasizes the establishment of a model evaluation system and solutions to voice latency issues, including pre-generation, cursor animation, and dual model combination. Finally, the article explores Silicon Valley's view on multi-model hybridization, future model development, AI company interview trends, the importance of Post Training, the current situation of Chinese people in Silicon Valley, and the reasons for Ted's departure from Character.ai. Ted believes that multi-model hybridization is the future trend, AI company interviews focus more on practical experience and problem-solving approaches, and there is a high demand for Post Training talent. He also announces an online AMA event hosted by him on December 7th, primarily for non-investor groups.
LWiAI Podcast #190 - AI scaling struggles, OpenAI Agents, Super Weights
The 190th episode of the Last Week in AI (LWiAI) podcast provides a comprehensive overview of the latest news and developments in the AI industry. Hosted by Andrey Kurenkov and Jeremie Harris, the episode covers a wide range of topics, from the challenges faced by major AI companies like OpenAI and Google in scaling their AI models, to the introduction of new AI tools and advancements in AI hardware. Key discussions include OpenAI's struggle to build more advanced AI models, the upcoming launch of OpenAI Agents designed to automate tasks for users, and Google's release of the Gemini model, which challenges OpenAI's dominance in the chatbot arena. The podcast also touches on strategic implications of AI hardware, including updates from NVIDIA and Google on new chips that significantly boost AI training performance, and the open-sourcing of DeepMind's AlphaFold3, which is expected to revolutionize drug discovery and molecular biology. In terms of policy and safety, the episode addresses the complex dynamics of AI regulation, including OpenAI's plans to present a U.S. AI strategy and an alliance to compete with China, and the departure of key safety researchers from OpenAI.