BestBlogs.dev Highlights Issue #9
Subscribe NowDear friends,
👋 Welcome to this edition of BestBlogs.dev's curated article selection!
🚀 This issue focuses on the latest developments in artificial intelligence, innovative applications, and business dynamics. Let's dive into the breakthrough progress in AI technology and explore the strategic moves of industry giants and innovative enterprises.
🔥 Breakthrough Progress in AI Models We spotlight several important AI model updates: Baidu released ERNIE 4.0 Turbo, highlighting significant improvements in speed and effectiveness. DeepSeek-Coder-v2 outperformed GPT-4 Turbo in coding capabilities, showcasing the immense potential of open-source models. Google introduced Gemma 2, an open-source large language model, offering developers a new alternative. Anthropic launched Claude 3.5 Sonnet, featuring the new Artifact functionality, expanding AI's application scope.
💡 AI Development Tools and Frameworks LangChain's introduction of the LangGraph v0.1 framework and LangGraph Cloud service opens new possibilities for building sophisticated AI agent systems. We'll also explore optimizations in RAG (Retrieval-Augmented Generation) methods and several noteworthy AI crawler open-source projects. These tools and methods are crucial for enhancing the performance and practicality of AI applications.
🏢 Innovative AI Applications in Specific Domains Financial Innovation: In-depth analysis of multi-agent technology applications in finance, discussing improvements in decision-making accuracy and efficiency. Gaming Industry: Exploring how AI is transforming games into personalized artistic experiences and its impact on game development. AI Hardware: Focusing on future trends in AI hardware development and discussing support for more complex AI applications.
📊 AI Market Dynamics and Business Strategies Large Model Market Competition: Analyzing the current price war and various collaboration models. Platform Roles: Examining how DingTalk and Feishu are attracting large model vendors to build AI ecosystems. AI Startups: Analyzing the opportunities and challenges facing AI startups, with special attention to the rise of AI search companies like Perplexity.
🔮 Future Outlook for AI Edge Models: Industry experts predict the development of GPT-4 level edge models by 2026. AI Application Proliferation: Discussing the potential timeframe and necessary conditions for widespread AI application adoption. AGI Development: Exploring the development prospects of Artificial General Intelligence (AGI) and its potential impact.
This issue covers the latest advancements in AI technology, innovative applications, and market dynamics, aiming to provide you with comprehensive and in-depth insights into the AI field. Whether you're a developer, product manager, or an AI enthusiast, we believe you'll find valuable information and inspiration here. Let's explore the limitless possibilities of AI technology together!
Table of Contents
- Announcing LangGraph v0.1 & LangGraph Cloud: Running agents at scale, reliably
- What is an agent?
- Baidu Releases Wenxin Model 4.0 Turbo: Faster and Better Performance
- Exploration of Multi-Agent System Applications in Financial Scenarios
- Optimizing RAG Through an Evaluation-Based Methodology
- Introducing llama-agents: A Powerful Framework for Building Production Multi-Agent AI Systems
- Figma AI: Empowering Designers Everywhere
- DeepSeek-Coder-v2 Tops the Arena as the Strongest Open-Source Coding Model, Surpassing GPT4-Turbo
- Open Model Bonanza, Private Benchmarks for Fairer Tests, More Interactive Music Generation, Diffusion + GAN
- AIGC Weekly #77
- 70 Years, 800 AI Models, Global AI Model Data Visualization; The Truth of AI Revealed by 750 Engineers; A Must-Read Manual for Founders Heading to the US | ShowMeAI Daily
- Welcome Gemma 2 - Google’s new open LLM
- Price Wars, Layoffs, and Model Failures: A Busy Q2 in the AI Community
- Sinovation's Wang Hua on the Future of AI Applications
- Z Potentials | Luyu Zhang: Serving Millions of Developers and Re-entering Entrepreneurship to Build the Leading Large Model Middleware, Dify, with No.1 Global Monthly Growth and Over 400,000 Installations
- Dialogue with Li Dahai of Mianbi Intelligence: Beyond Scaling Law, Another Key Path for Large Models
- Reflections on the Next Generation AI Hardware: A Conversation Between Two Hardware Entrepreneurs
- AI Will Reshape Gaming: Marc Andreessen's 15,000-Word Discussion on Game Products and Investment in the AI Era (Video Included)
- Why is Feishu the Shared Choice of China's Large Language Model Unicorns?
- Podcast Update: An Oral Account of the First Half of the Global Large Model: Perplexity's Sudden Popularity and the Yet-to-Boom AI Application Ecosystem
Announcing LangGraph v0.1 & LangGraph Cloud: Running agents at scale, reliably
The article outlines the launch of LangGraph v0.1 and LangGraph Cloud, two key tools designed to enhance agentic workflows for AI systems. LangGraph offers developers granular control over agentic tasks, including decision-making logic, human-agent collaboration, and error recovery. It supports both single-agent and multi-agent architectures, ideal for complex applications. LangGraph Cloud, designed for scalable deployment, manages fault tolerance, task distribution, and real-time debugging. Key testimonials from major companies like Replit, Norwegian Cruise Line, and Elastic showcase the platform's value in real-world AI use cases, while the article encourages developers to experiment with LangGraph via GitHub and LangGraph Cloud’s waitlist.
What is an agent?
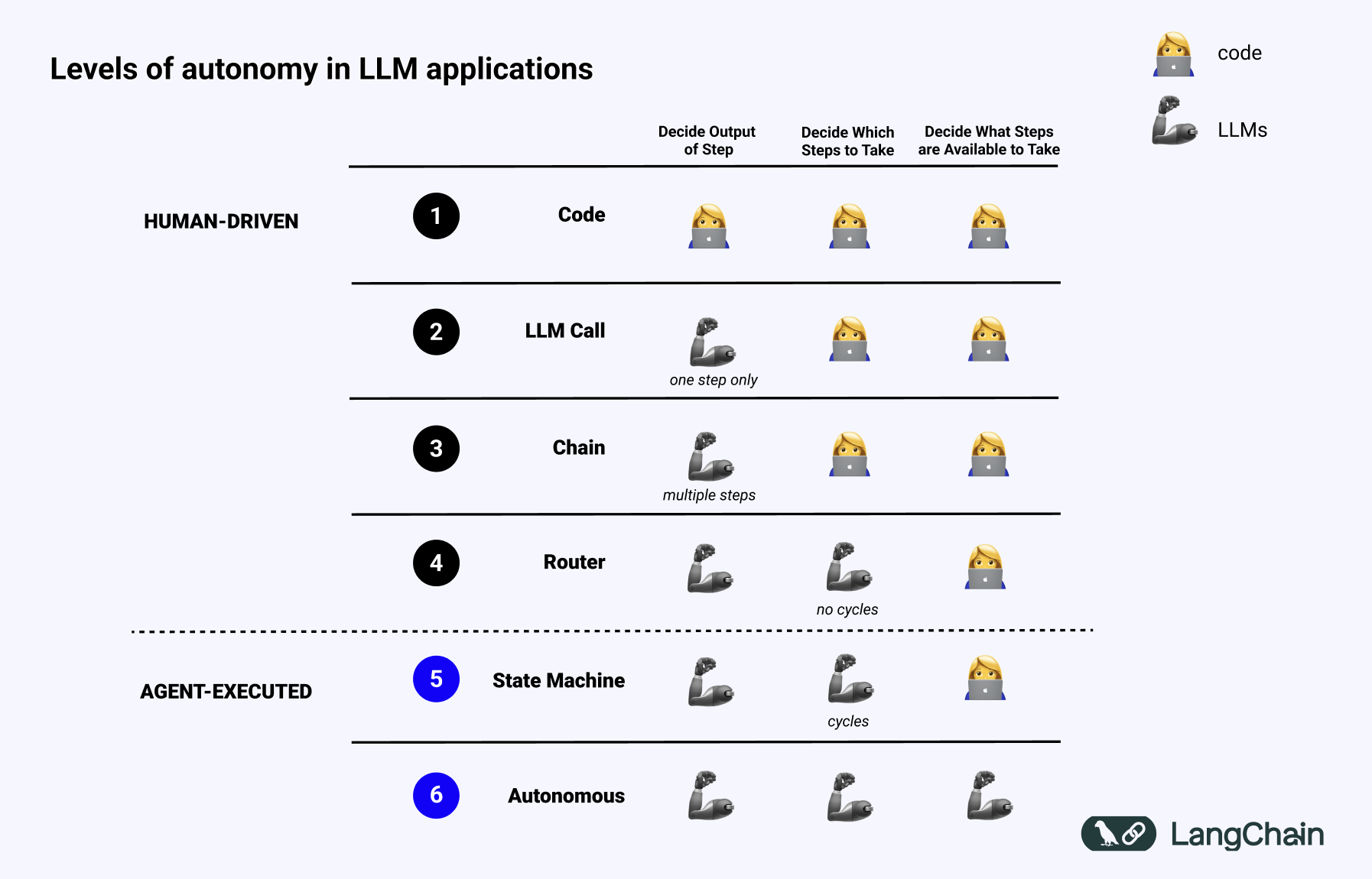
This article from the LangChain Blog tackles the definition and understanding of 'agents' in LLM applications. The author, a LangChain developer, defines an agent as a system that uses an LLM to guide the control flow of an application, contrasting it with the perception of agents as advanced, human-like entities. The article introduces the concept of 'agentic' capabilities as a spectrum, similar to levels of autonomy in self-driving cars, advocating for its use in guiding the development, execution, and evaluation of LLM systems. It further highlights the need for new tools and infrastructure like LangChain's LangGraph and LangSmith to support increasingly agentic applications. The more 'agentic' an application, the more critical specialized tools become for managing its complexity.
Baidu Releases Wenxin Model 4.0 Turbo: Faster and Better Performance
At WAVE SUMMIT 2024, Baidu introduced the Wenxin Model 4.0 Turbo, emphasizing improvements in speed and performance. The model achieved optimization through innovations in data, basic models, alignment technology, knowledge, and dialogue. The conference also presented various innovations, including Agricultural AI, PaddlePaddle Framework 3.0, and the intelligent code assistant 'Wenxin Fast Code' 2.5. These technologies demonstrate Baidu's progress in AI models and applications, promoting the development of AGI. The daily user inquiries for Wenxin Model increased by 78%, and the average inquiry length rose by 89%, indicating its growing application and user demand.
Exploration of Multi-Agent System Applications in Financial Scenarios
This article details the speech by Chen Hong, a senior algorithm expert at Ant Group, at the AICon Global AI Development and Application Conference, discussing the application of multi-agent system technology in the financial field. The article focuses on the role of multi-agent systems in addressing challenges of information, knowledge, and decision-intensive environments in finance. By examining the technical evolution of large models and agents, the article highlights the stateful nature of agents and their critical role in task execution. Subsequently, the article proposes solutions for multi-agent system applications in financial scenarios, especially the application of the PEER Model in enhancing the rigor and professionalism of financial decision-making. Finally, the article showcases practical application cases of Ant Group based on the AgentUniverse (a multi-agent framework) framework, illustrating how the PEER Model improves analyst productivity across multiple financial scenarios.
Optimizing RAG Through an Evaluation-Based Methodology
The article begins by examining the role of AI in knowledge management, highlighting the potential of the Retrieval Augmented Generation (RAG) method to improve the quality of text generation. By enabling Large Language Models (LLMs) to access information from repositories such as vector databases, RAG enhances the accuracy, relevance, and reliability of generated text. The author underscores the critical importance of evaluation strategies in ensuring that AI products achieve success benchmarks. The article illustrates, through an experiment, how the RAG system can be optimized using tools like Qdrant and Quotient. Qdrant functions as an efficient vector database, ideal for the quick and precise retrieval of large datasets necessary for RAG solutions. Quotient provides tools to evaluate and refine RAG implementations, assisting teams in identifying deficiencies and improving their applications' performance.
Through the experiment, the author constructs a RAG pipeline and employs Qdrant and Quotient for assessment, leading to a set of critical insights. These include the identification of irrelevant documents and hallucinations, strategies for optimizing document retrieval, the necessity for adaptive retrieval, the effects of variations in models and prompts on the quality of responses, and the optimization tools offered by Qdrant and Quotient. A series of experiments explores the impact of different parameter settings—such as embedding models, chunk size, chunk overlap, and the number of retrieved documents—on RAG performance, as well as the influence of various LLMs. The results demonstrate that careful adjustment of these parameters and models can significantly enhance the RAG system's effectiveness.
Introducing llama-agents: A Powerful Framework for Building Production Multi-Agent AI Systems
In the AI domain, LlamaIndex's open-source framework llama-agents is revolutionizing the development process for multi-agent AI systems. It provides developers with a robust toolkit that features a distributed service-oriented architecture, standardized API communication protocols, and adaptable orchestration workflows. This makes the creation of complex AI systems both more efficient and more reliable. Regardless of the application, whether it's question-answering systems, collaborative AI assistants, or distributed AI workflows, llama-agents empowers developers to transform agents into scalable microservices. Additionally, it offers straightforward deployment and real-time monitoring solutions.
Figma AI: Empowering Designers Everywhere
At Config2024, Figma announced a range of new features, including Figma AI, aimed at solving real-world problems faced during the design process to enhance efficiency and creativity. Figma AI streamlines the workflow for designers with features such as visual and AI-enhanced content search, auto-naming layers, text processing, and visual layout generation. Additionally, Figma has made five major optimizations to the UI interface, making it easier for users to get started. Figma also released a new version of Figma Slides, further enhancing its competitiveness in the professional environment. Figma has committed to data privacy protection to ensure the security of user data.
DeepSeek-Coder-v2 Tops the Arena as the Strongest Open-Source Coding Model, Surpassing GPT4-Turbo
DeepSeek-Coder-v2 has emerged as the strongest open-source coding model in the Arena, surpassing GPT4-Turbo. It supports 338 programming languages and offers 236B and 16B parameter sizes. The model excels in coding and mathematics, ranking high in various coding and AI performance benchmarks. DeepSeek-Coder-v2 also introduced a feature similar to 'Artifacts', allowing code generation and execution directly in the browser.
Open Model Bonanza, Private Benchmarks for Fairer Tests, More Interactive Music Generation, Diffusion + GAN
This article from The Batch Newsletter discusses the advancements in AI coding agents, particularly focusing on open-source frameworks like OpenDevin. It highlights research papers that explore multi-agent code generation, code debugging using large language models (LLMs), and the development of efficient agent-computer interfaces. The article emphasizes the importance of automated evaluation using benchmarks like HumanEval and MBPP, contrasting it with the challenges of evaluating web search and article synthesis agents. It concludes by discussing the rapid evolution of coding agents and their potential to make programming more enjoyable and productive.
AIGC Weekly #77
This week in AIGC, Anthropic releases Claude 3.5 Sonnet with improved performance and a new interactive feature called Artifact. Runway launches its video generation model Gen-3, boasting high video quality and fine-grained control. Deepseek unveils its code model and code assistant, DeepSeek-Coder-V2, surpassing GPT-4 turbo in code capabilities. Ilya Sutskever establishes a new company, SSI, focusing on safe superintelligence. Meta open-sources four models, including the Meta Chameleon language model, the Meta Multi-Token Prediction model for code completion, the Meta JASCO music model, and the AudioSeal audio watermarking technology. Other notable developments include new features from Kuaishou's Kelin, Midjourney, and Google Gemini, and the formation of Comfy Org. The report concludes with recommendations for AI-powered tools such as Genspark, Hedra, Dot, Otto, Playmaker Document AI, and selected readings like Andrej Karpathy's LLM 101 course and Lex Fridman's interview with the CEO of Perplexity.
70 Years, 800 AI Models, Global AI Model Data Visualization; The Truth of AI Revealed by 750 Engineers; A Must-Read Manual for Founders Heading to the US | ShowMeAI Daily
The daily report from ShowMeAI unveils the latest developments in AI technology: Anthropic's large-scale model, Claude Artifacts, takes the lead in the programming field by generating and previewing code, heralding a new era for AI applications in workflow processes. Global visualizations of AI model data highlight a swift upward trend in the training computation and costs, especially for language models.
Survey results indicate that while AI's role in boosting work efficiency is widely acknowledged, there remains a prevalence of AI usage without clear policy direction. The increasing application frequency of AI in chatbots and workflow automation underscores its growing importance in daily operations.
Furthermore, the article underscores that generative AI (GenAI) should not be seen as a substitute for junior programmers; effective engineering teams still hinge on human collaboration. For American startup founders, the report offers practical guidance on company incorporation, stock distribution, and more, assisting them in making wise decisions at the outset of their entrepreneurial journey.
Welcome Gemma 2 - Google’s new open LLM
Google has recently unveiled its latest open-source, large-scale language model, Gemma 2, which is available in two sizes: 90 billion and 270 billion parameters, each with a base version and an instruction-tuned version. Gemma 2 introduces key enhancements in sliding window attention mechanisms, logarithmic probability soft constraints, knowledge distillation, and model merging, all designed to improve generation quality and overall model performance. The article offers a detailed account of Gemma 2's architecture, training process, and advancements in technology. Gemma 2 is trained on Google Cloud TPUs and is seamlessly integrated with Hugging Face Transformers, as well as being compatible with Google Cloud and inference endpoint integration.
The technical innovations in Gemma 2 encompass: sliding window attention, which combines local and global attention to enhance long text processing; logit soft-capping, which improves training by curbing the growth of logits; knowledge distillation, which has been employed to refine the pre-training of the 90 billion parameter model; and model merging, which leverages the combination of multiple models to enhance performance. Gemma 2 utilizes a novel merging technique known as WARP, which incorporates exponential moving average, spherical linear interpolation (SLERP), and linear interpolation towards initialization.
Price Wars, Layoffs, and Model Failures: A Busy Q2 in the AI Community
The second quarter of 2024 witnessed a flurry of activity in the AI field, highlighting both technological progress and fierce market competition. Meta unveiled the open-source large language model Llama 3, touted as an 'open-source GPT-4.' Meanwhile, Microsoft released the open-source model WizardLM-2, but quickly removed it due to a lack of toxicity testing, sparking widespread discussion. Mobvoi, a company specializing in generative AI and voice interaction technology, successfully listed on the Hong Kong stock market, becoming the first AIGC company to go public. Google's decision to lay off its entire Python team underscored the fact that competition in the AI field extends beyond technology, encompassing factors like labor costs and market strategies. Companies like Alibaba Cloud demonstrated their technical prowess by releasing new models and upgrading services. OpenAI's GPT-4o model further enhanced the capabilities of generative AI, showcasing its advanced abilities in text, vision, and audio. Domestic tech giants like Alibaba, Baidu, and Tencent significantly reduced the prices of large models, drawing market attention. The United States passed the ENFORCE Act, strengthening control over AI technology exports. Mistral released the first generative AI model for coding, Codestral. Zhipu AI launched MaaS 2.0 and reduced prices comprehensively, leading to a significant increase in API call volume. Apple demonstrated its emphasis on AI technology at the WWDC24 Developer Conference. Former OpenAI Chief Scientist Ilya Sutskever established a new company, SSI, forming competition with OpenAI. Domestic large model companies have swiftly rolled out migration plans to mitigate the impact of OpenAI's supply disruption, offering alternative solutions for developers and businesses.
Sinovation's Wang Hua on the Future of AI Applications
At AGI Playground 2024, Wang Hua of Sinovation Ventures provided insights into the explosion of AI applications, emphasizing four prerequisites: model performance, inference cost, multi-modality technology, and a robust application ecosystem. He noted that as inference cost decreases, AI applications will become more widespread, particularly when large model inference costs drop to 1% of their current levels within the next few years, unlocking more consumer-facing applications. Wang Hua also highlighted that China is entering the early phase of a significant AI application boom, with rapid development expected over the next two to three years, especially in B2B and productivity tools. He further stressed that AI entrepreneurs must balance product vision with technical expertise to address the unique challenges of large model entrepreneurship.
Z Potentials | Luyu Zhang: Serving Millions of Developers and Re-entering Entrepreneurship to Build the Leading Large Model Middleware, Dify, with No.1 Global Monthly Growth and Over 400,000 Installations
In the realm of artificial intelligence, Dify has emerged as a leading startup focused on middleware for large-scale models, achieving over 400,000 installations in just one year and securing its position as the fastest-growing provider of open-source middleware for large-scale models globally. In an interview, Dify's founder, Zhang Luyu, delved into his entrepreneurial journey, his perspectives on the evolution of AI technology, and the company's vision. Zhang highlighted the principle of user-centered product design, stressing the importance of balancing user-friendliness with adaptability in a rapidly changing technological landscape. He proposed the concept of LLMOps, noting the consolidation of AI technology stacks and the intricate engineering challenges inherent in middleware. Additionally, he underscored the critical role of open-source practices and globalization.
The article detailed Zhang's insights into the three driving forces behind entrepreneurship: a desire to improve upon the status quo, a passion for creation, and a commitment to altruism. He particularly emphasized the centrality of altruism in his entrepreneurial ethos. Zhang posited that an effective tool should streamline user tasks rather than fabricate demand. While acknowledging the maturation of the AI technology stack, he pointed out that the integration of models and applications continues to pose significant challenges—a niche that Dify is dedicated to addressing. He also highlighted the strategic importance of open source for Dify, crediting it with fostering global contributor engagement, enhancing technical control, and reducing barriers to market-driven promotion.
Zhang expressed a keen interest in fostering a culture of innovation and teamwork within his company, recognizing the pivotal role of team culture in a startup's success and the necessity of continuous innovation for staying competitive. Furthermore, he shared his reflections on the release of ChatGPT, expressing his belief that recent advancements in AI have unlocked unprecedented opportunities for innovators and entrepreneurs, inspiring a surge of creativity and boldness across the industry.
Dialogue with Li Dahai of Mianbi Intelligence: Beyond Scaling Law, Another Key Path for Large Models
In this article, Li Dahai from Mianbi Intelligence discusses the future of large models beyond the Scaling Law. Key points include:
- The potential to develop a GPT-4 level edge model by 2026.
- The importance of edge models in being closer to users and more practical.
- The role of AGI and the significance of Agent technology.
- The concept of 'intelligent density' and its impact on the efficiency of large models.
- The challenges and advancements in creating efficient edge models with high performance.
Reflections on the Next Generation AI Hardware: A Conversation Between Two Hardware Entrepreneurs
At the AGI Playground 2024 Conference, hardware entrepreneurs Yang Jianbo and Yang Meng engaged in a deep discussion about the future of AI hardware. They believe that AI hardware needs to offer efficient human-computer interaction and emotional value to meet user needs across various scenarios. While smartphones remain the optimal interaction device, AI hardware can provide emotional value in non-work settings, such as AI pets. The emergence of large AI models has revolutionized the traditional development of AI algorithms, enabling more problems to be solved through innovations in underlying models. They also discussed how AI can enhance different roles, particularly the emotional value of pets and intelligent entities. They predict that future intelligent entities might be a single super intelligent agent coordinating all scenarios, or multiple isolated intelligent agents. The development of AI hardware requires a combination of local computing power and cloud models to deliver an enhanced user experience. The organizational structure of hardware companies will not undergo rapid changes in the AI era; they will continue to rely on experienced individuals and existing tools. AI cannot fully replace human resources in hardware companies in the short term, and the foundation of organizational structure remains crucial.
AI Will Reshape Gaming: Marc Andreessen's 15,000-Word Discussion on Game Products and Investment in the AI Era (Video Included)
Marc Andreessen shared his deep insights on the impact of AI in the gaming sector during his interview. He posited that AI would revolutionize gaming, turning it into an individualized art form that can respond dynamically to players, fostering a collaborative cycle of creation between the users and the system. Andreessen espoused a philosophy of technological optimism, noting that while new technologies might provoke moral panic, their positive transformations are substantial. He likened AI to a novel breed of computer that can creatively generate content, thus paving the way for novel artistic expressions and business paradigms. He also highlighted the critical role of open-source initiatives in advancing the widespread adoption and innovation of AI technologies, expressing optimism about the opportunities for startups in this space. Furthermore, Andreessen predicted that founders in the gaming industry could exert a significant influence on the world over the next few decades, and he explored the potential for gaming technology to permeate other fields, thereby driving social advancement.
Why is Feishu the Shared Choice of China's Large Language Model Unicorns?
Feishu, a collaboration platform developed by ByteDance, has become the preferred choice for leading Chinese large language model (LLM) companies. This article explores the reasons behind this trend, highlighting the unique challenges faced by LLM startups and how Feishu addresses them. The article details three key aspects of Feishu's appeal:
- Rapid Iteration and Organizational Agility: Feishu's tools and methodology facilitate rapid iteration, enabling LLM companies to adapt quickly to the fast-paced nature of the industry.
- Context Over Control: Feishu's all-in-one approach fosters information flow and efficient collaboration, aligning with the decentralized, goal-driven nature of LLM companies.
- Flexibility and Openness: Feishu's high degree of flexibility and openness, particularly its multi-dimensional table and open platform capabilities, caters to the technical expertise and customization needs of LLM companies.
Podcast Update: An Oral Account of the First Half of the Global Large Model: Perplexity's Sudden Popularity and the Yet-to-Boom AI Application Ecosystem
This episode of 'Zhang Xiaojun Jùn | Business Interview' is a podcast from Tencent News focusing on in-depth business interviews, aiming to depict the business, culture, and new knowledge of our era. The podcast discusses the progress of global large models in the first half of the year from the perspective of AI applications. It delves into Perplexity, a company in the AI search domain, and its startup, data, competition, and moat. Perplexity's latest valuation has reached $3 billion. The podcast also addresses concerns in the industry, such as why AI applications have not yet boomed, why GPT-5 is slow, and what the business model and barriers of large models are. Additionally, it reviews the status of major U.S. tech giants in the past six months.